최고의 Stable Diffusion 모델 (2026): 현실적, 애니메이션 및 그 이상을 위한 추천 모델

업데이트됨
적합한 Stable Diffusion 모델을 선택하는 것은 결과를 즉시 좌우할 수 있습니다. 얼굴이 흐릿하거나, 스타일이 일관되지 않거나, 여러 체크포인트를 테스트하는 데 시간이 너무 많이 걸린다면, 그 문제는 대개 프롬프트가 아니라 모델 자체에 있습니다.
2026년에는 몇 가지 Stable Diffusion 모델들이 명확하게 두각을 나타냅니다: SDXL은 여전히 가장 우수하고 초보자 친화적인 옵션이며, Realistic Vision / RealVisXL은 포토리얼리스틱 이미지에서 뛰어난 성능을 보이고, Anything v5 / AAM XL은 애니메이션 스타일에 최적화되어 있으며, Juggernaut XL은 시네마틱하고 고세밀한 결과를 제공합니다.
이 가이드는 단순한 긴 목록이 아닙니다 — 테스트되고 분류된 분석으로, 당신의 정확한 용도에 맞는 최고의 Stable Diffusion 모델을 빠르게 찾을 수 있도록 도와줍니다.
시간이 부족하고 하이라이트만 보고 싶다면, 여기에 시도할 가치가 있는 최고의 모델들에 대한 간단한 분류가 있습니다. 아래 각 카테고리는 성능, 스타일, 커뮤니티 피드백을 기반으로 뛰어난 선택을 나타냅니다. 최고의 Stable Diffusion 모델은 당신의 목표에 따라 다릅니다:
- 최고의 전반적 모델: SDXL
- 다용도 및 창작자 중심 모델: Z-Image (초상화, 제품, 스타일화된 아트, 그래픽 출력에서 뛰어남)
- 최고의 현실적인 모델: Realistic Vision / RealVisXL V4.0
- 최고의 애니메이션 모델: Anything v5 / AAM XL AnimeMix
- 최고의 판타지 및 공상과학 모델: DreamShaper
- 최고의 사진적 및 시네마틱 모델: Juggernaut XL v9
- 최고의 4K / 고해상도 모델: ThinkDiffusion XL (커뮤니티 훈련된 고해상도 전문가)
- 2025년 최고의 신생 모델: SD 3.5 Large (SDXL을 넘는 다음 진화)
- 최고의 다목적 프로용 스위트: Flux 1.1 Pro / Ultra / Raw
- 차세대 아키텍처: Flux 2 (복잡한 장면에서 더 안정적이고 빠르며 선명함)
확실하지 않다면, SDXL로 시작한 후 LoRA 모델을 사용해 결과를 세밀하게 조정하세요.
역대 최고의 6대 Stable Diffusion 모델
어떤 모델을 선택해야 할지 모르겠다면, 이 간단한 비교가 도움이 될 것입니다:
| 모델 | 최고의 용도 | 강점 | 약점 |
|---|---|---|---|
| SDXL | 다용도 | 스타일 전반에 걸쳐 다재다능하고 고품질의 출력 | 텍스트 렌더링 약함 |
| Z-Image | 다용도 및 빠른 생성 | 빠른 추론, 강력한 프롬프트 정렬, 좋은 사실감 | 작은 생태계, LoRA 지원 부족 |
| Realistic Vision | 포토리얼리즘 | 뛰어난 사람 얼굴과 사실적인 세부 묘사 | 스타일 유연성 부족 |
| DreamShaper | 판타지 및 일러스트 | 강력한 예술적 스타일, 공상과학 및 창의적인 장면에 적합 | 덜 현실적인 출력 |
| Anything v5 | 애니메이션 | 강력한 애니메이션 스타일과 생동감 있는 비주얼 | 현실적인 스타일에는 적합하지 않음 |
| Juggernaut XL | 시네마틱 이미지 | 고세밀한 디테일, 시네마틱 조명 및 구도 | 자원 집약적 |
SDXL — 최고의 전반적인 Stable Diffusion 모델
초보자, 일반 창작자 및 과도한 최적화 없이 신뢰할 수 있는 결과를 원하는 사람들에게 최적
단 하나의 모델만 설치하고 싶다면, SDXL은 2026년에도 여전히 가장 안전한 선택입니다. 거의 모든 용도에서 신뢰할 수 있는 성능을 보이며 — 초상화와 제품 사진에서부터 풍경과 스타일화된 아트까지 — 복잡한 프롬프트나 과도한 튜닝 없이도 뛰어난 결과를 제공합니다. 이는 초보자에게 이상적인 출발점이 되며, 경험이 풍부한 창작자들에게도 충분히 강력한 모델입니다.
Stability AI의 플래그십 모델인 SDXL은 뛰어난 다재다능성과 다양한 스타일(현실감, 애니메이션, 일러스트 등)에서 높은 디테일의 사실적인 이미지를 생성할 수 있는 능력으로 잘 알려져 있습니다. 1024×1024 이미지를 기반으로 훈련되어 강력한 전반적인 품질과 일관성을 제공합니다. 그러나 여전히 정확한 텍스트 렌더링에는 어려움이 있습니다.
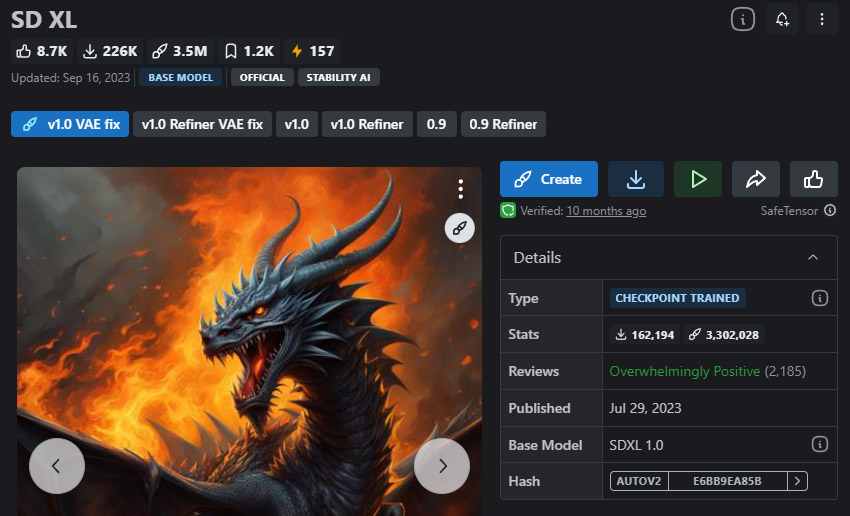
- 1024×1024 해상도에서 일관되게 고품질 이미지를 제공합니다.
- 대부분의 모델보다 현실감과 예술적 스타일을 더 잘 처리합니다.
- 강력한 생태계 지원 (LoRA, 세부 조정, 도구).
- 텍스트 생성이 여전히 신뢰할 수 없습니다.
- SDXL 호환 LoRA가 필요합니다.
- 이전 SD 1.5 모델들보다 약간 더 무겁습니다.
Z-Image — 속도와 품질을 겸비한 최고의 다용도 모델
모든 용도와 창작자 중심 모델, 빠르고 고품질의 이미지 생성을 위한 새로운 S3-DiT 아키텍처 기반
Z-Image는 새로운 S3-DiT(Scalable Single-Stream Diffusion Transformer) 백본을 기반으로 구축된 차세대 모델입니다. 전통적인 듀얼 스트림 아키텍처와 달리, Z-Image는 텍스트와 이미지 입력을 처음부터 단일 통합 경로를 통해 처리합니다. 이 단순화되고 고효율적인 설계 덕분에 모델은 더 빠르게 실행되면서도 인상적인 시각적 충실도를 유지합니다.
6억 개의 파라미터만을 갖춘 Z-Image는 가볍지만 놀라운 성능을 발휘하며, 일관된 포토리얼리즘, 강력한 스타일 제어, 그리고 유사한 크기의 많은 모델들보다 더 나은 텍스트 렌더링 성능을 제공합니다. 복잡한 프롬프트 없이 초상화, 제품 사진, 스타일화된 비주얼 및 상업용 콘텐츠를 제작하는 창작자들에게 특히 매력적입니다.
이 모델은 세 가지 변형으로 제공됩니다: Z-image Turbo, 8단계 추론에 최적화된 빠른 버전으로 RTX 4090과 같은 소비자용 GPU에 이상적입니다; Z-image Base, 세부 조정과 LoRA 훈련에 적합한 비증류 버전; 그리고 Z-image Edit, 명령 기반 이미지 편집을 위해 설계된 특수 모델입니다.
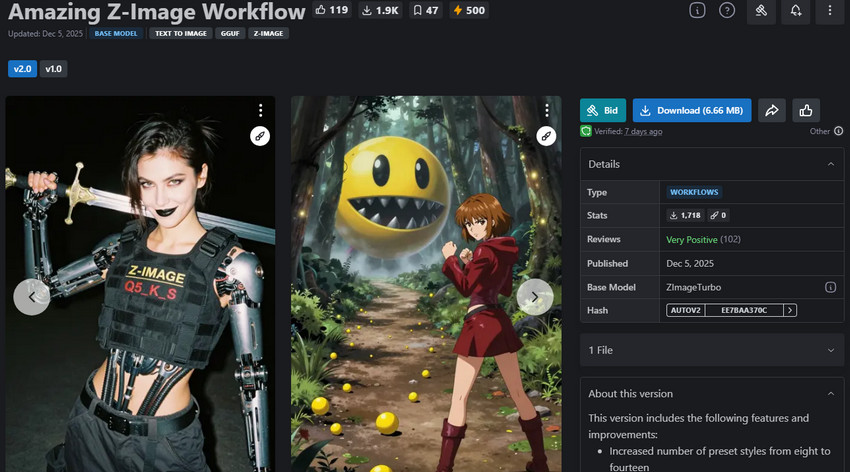
- 빠르고 고품질의 출력을 제공하는 효율적인 S3-DiT 아키텍처.
- 초상화, 제품, 스타일화된 상업용 비주얼에 탁월함.
- Turbo, Base, Edit을 포함한 여러 변형을 지원.
- 텍스트 렌더링은 개선되었지만 여전히 완전히 신뢰할 수 없음.
- 손 자세와 복잡한 다중 객체 장면은 다듬기가 필요할 수 있음.
- SDXL에 비해 LoRA 생태계가 더 작음.
Realistic Vision — 포토리얼리즘 이미지에 최적화된 모델
최고의 용도: 초상화, 제품 사진, 라이프스타일 사진, 상업적 비주얼
만약 목표가 실제 사진처럼 보이는 이미지를 생성하는 것이라면, Realistic Vision은 가장 신뢰할 수 있는 모델 중 하나입니다. 이 모델은 자연스러운 피부 톤과 얼굴 디테일, 사실적인 조명과 그림자, 의류 질감과 세부 사항을 렌더링하는 데 탁월합니다. SDXL과 비교하여, 더 적은 프롬프트 노력으로 더 사실적인 인간을 생성할 수 있습니다.
하지만 판타지나 스타일화된 아트에는 적합하지 않으며, 다양한 스타일에 대한 유연성이 떨어지는 등 고려해야 할 한계점도 있습니다.
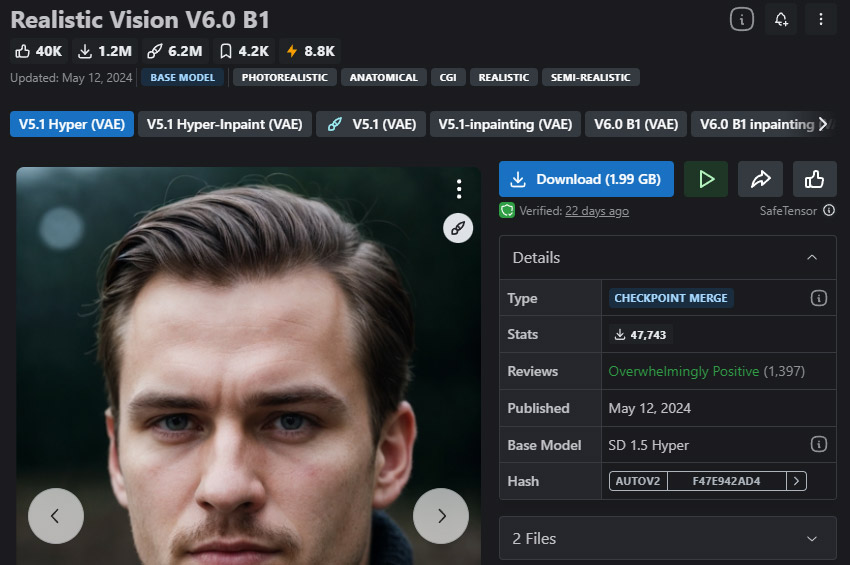
- 현실적인 인간을 생성하는 데 매우 적합합니다.
- 생성된 이미지는 매우 세밀하고 사실적입니다.
- NSFW 지원.
- 인페인팅 버전 제공.
- 판타지 환경이나 이미지를 생성할 수 없습니다.
DreamShaper — 판타지 및 일러스트에 최적화된 모델
판타지와 일러스트 세계 및 공상과학 장면을 위한 최고의 Stable Diffusion 모델.
DreamShaper는 공상과학 및 사이버펑크 스타일 비주얼과 같은 특별한 세계를 찾는 사람들에게 최고의 선택입니다. 독특한 디자인을 통해 신비로운 환경, 전설적인 생물, 환상적인 풍경을 창조하려고 합니다. DreamShaper는 애니메이션에서 영감을 받아 현실적인 회화 스타일로 아트워크를 연상시키는 비주얼을 만들도록 세심하게 설계되었습니다. 이 모델의 인상적인 능력은 숨막히는 배경을 배경으로 한 캐릭터를 창조하는 데 있습니다.
Stable Diffusion 모델은 사실적인 묘사에서부터 창의적이고 꿈 같은 구성을 특징으로 하는 이미지를 만드는 데 뛰어난 도구로, 독특한 존재들, 동물들, 물체들, 풍경들 등을 포함한 다양한 주제를 아우르는 이미지를 생성할 수 있습니다.
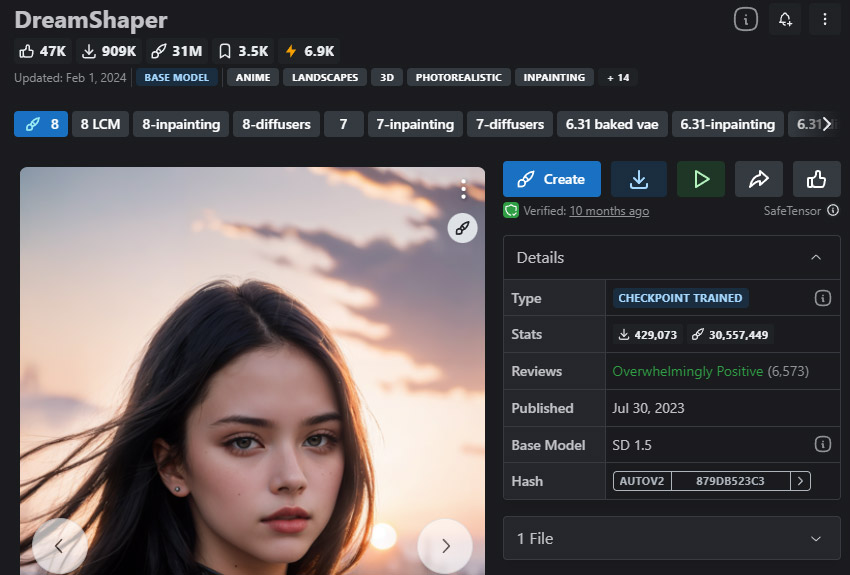
- 공상과학 및 사이버펑크 테마 생성에 탁월함.
- 포토리얼리즘과 애니메이션 스타일 모두에 이상적입니다.
- 인페인팅 버전 제공.
- NSFW 지원.
- 현실적인 이미지를 생성하는 데는 적합하지 않습니다.
Anything v5 — 애니메이션 스타일에 최적화된 모델
애니메이션 스타일과 만화 같은 외관을 위한 최고의 Stable Diffusion 모델.
Anything v5는 당신이 사랑하는 애니메이션과 만화의 본질을 불러일으키는 매력적인 비주얼을 생성하기 위해 설계된 맞춤형 Stable Diffusion 모델입니다. 생동감 있는 색상, 표현력 있는 캐릭터, 그리고 애니메이션 세계에 생명을 불어넣는 다이내믹한 구성들이 특징입니다. 특히 이 모델은 일본 애니메이션에서 자주 볼 수 있는 장면을 창조하려는 의도로 설계되었습니다.
Anything v5는 애니메이션 또는 일러스트 스타일로 캐릭터와 풍경을 생성할 수 있습니다. 초상화를 생성할 때, 이 모델은 많은 복잡한 디자인 요소가 포함된 젊은 주인공을 생성하는 데 뛰어납니다. 애니메이션 외관에도 불구하고, Anything은 부드러운 색상 팔레트를 사용하여 아름다운 설정을 만들 수 있습니다.
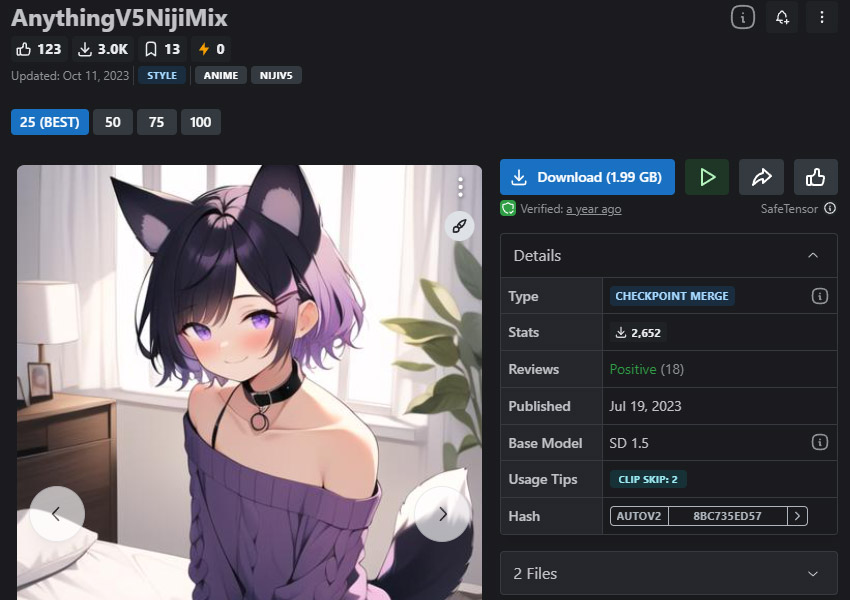
- 다양한 애니메이션 아트 스타일을 커버합니다.
- 현실감 있는 분위기로 애니메이션 캐릭터와 배경을 생성합니다.
- 화려한 색상으로 가득한 이미지를 생성할 수 있습니다.
- 복잡한 형태와 요소를 생성합니다.
- NSFW 지원.
- 여성 캐릭터 생성에 집중됩니다.
- 일본 장르에 일반적인 장면을 생성합니다.
- VAE와 함께 실험이 필요합니다.
Juggernaut XL
사진 스타일 이미지/실제 사진을 위한 최고의 Stable Diffusion 모델.
Juggernaut XL은 SDXL 모델을 뛰어넘는 예외적인 후속 모델로, 그 한계를 확장하려는 사람들에게 최적입니다. 세련된 버전은 향상된 디테일과 충실도를 제공하며, 디지털 아트와 사진이 완벽하게 결합된 하이퍼리얼리즘 이미지를 생성하는 데 완벽합니다. 세밀한 디테일을 가장 선명하게 포착하는 뛰어난 능력 덕분에, 인간의 전체적인 모습, 물체, 로고 또는 풍경 등 다양한 주제를 생성하는 데 귀중한 도구가 됩니다. 이는 특히 독특하고 탁월한 마감을 요구하는 포토리얼리틱 초상화나 패션 일러스트를 만들 때 유리합니다.
Juggernaut XL은 영화적 이미지에 특화된 훈련을 통해 업그레이드되어, 결과물의 자연스러운 영화 품질을 높였습니다. 실제 사진의 본질을 포착하는 이미지를 만들고자 하는 사람들에게, Juggernaut XL은 몰입감 있는 경험을 제공합니다.
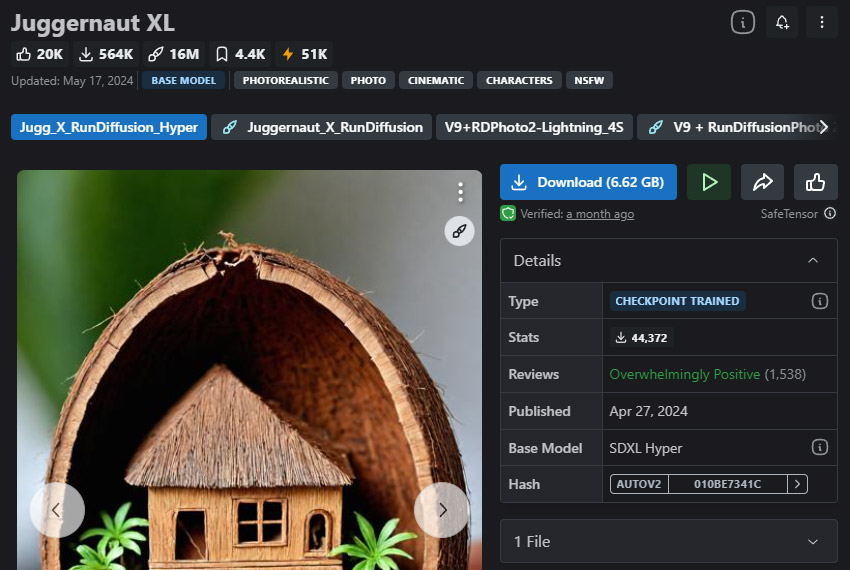
- 포토리얼리틱 스틸 사진과 영화 같은 느낌의 샷에 완벽합니다.
- 이미지 크기 변형을 손쉽게 처리합니다.
- SDXL LoRA 모델과 호환됩니다.
- NSFW 지원.
- 자원 소모가 큽니다.
- 항상 포토리얼리틱하지는 않습니다.
- 학습 곡선이 가파릅니다.
2026년에도 여전히 선도하는 Stable Diffusion 모델들
Stable Diffusion은 계속해서 발전하고 있으며, 2026년에는 이미 흥미로운 발전이 이루어졌습니다. 하드웨어 최적화된 출시부터 차세대 편집 기능까지, 여러분이 알아야 할 가장 큰 업데이트를 소개합니다.
LoRA 모델 (Low-Rank Adaptation)
LoRA 모델은 Stable Diffusion 생태계에서 핵심적인 부분이 되었습니다. 기본 체크포인트를 교체하는 대신, LoRA는 SD 3.5 Large와 같은 모델에 특정 스타일, 캐릭터 또는 개념을 추가하는 경량화된 부가 모듈로 작용합니다. 이로 인해 여러 무거운 모델을 관리하지 않고도 유연성을 원하는 창작자들에게 이상적인 선택이 됩니다.
LoRA 모델의 주요 특징:
- 기본 체크포인트에 비해 수백 MB에 불과한 경량 모델 확장.
- 예술 스타일, 캐릭터, 의류 또는 조명 등 특정 요소를 추가하거나 수정하도록 설계됨.
- 적층 가능하고 조정 가능하여, 다양한 강도 값으로 여러 LoRA를 결합할 수 있음.
- SD 3.5 Large, SDXL 및 세부 조정된 변형 모델과 완벽하게 호환됨.

SD 3.5 Large
SD 3.5 Large는 3.0 시리즈에서 큰 발전을 이루었으며, 다양한 스타일에서 품질과 다재다능성을 강조합니다. SD 3.5 Medium은 일상적인 창작자들을 위한 균형 잡힌 옵션을 제공하고, SD 3.5 Large Turbo는 속도에 중점을 두어 약간의 디테일을 줄이면서 더 빠른 반복 작업을 가능하게 합니다. 이들 변형 모델은 모두 취미로 사용하는 사람부터 산업 전문가까지 모든 수준의 사용자에게 적합한 SD 3.5 가족을 만듭니다.
SD 3.5 Large의 주요 특징:
- 2025년 Stability AI의 주요 출시 모델로, 더 넓은 데이터셋을 사용해 훈련되었으며 더욱 높은 충실도로 최적화됨.
- 이전 버전들보다 더 높은 정확도, 디테일 및 스타일 범위를 갖춘 이미지를 생성.
- 창의적이고 상업적인 프로젝트를 모두 지원하는 전문적인 사용을 위해 설계됨.
Flux 시리즈 (Flux 1.1 → Flux 2)
Flux 패밀리는 현대 확산 모델에서 가장 중요한 발전 중 하나를 대표하며, 인기 있는 Flux 1.1 시리즈에서 더 진보하고 안정적인 Flux 2로 진화했습니다. 각 세대는 창의적 표현력, 영화적 스타일링 및 프롬프트 유연성에 중점을 두고 있으며, Flux 2는 일관성, 디테일 품질, 속도에서 주요한 개선 사항을 도입했습니다. Flux 라인업은 스타일과 해상도에 걸쳐 일관된 제어를 원하는 예술가, 디자이너, 창작자들에게 다양한 옵션을 제공합니다.
Flux 1.1 시리즈:
- Flux 1.1 Pro: 넓은 프롬프트 범위와 영화적 렌더링을 위해 설계된 균형 잡힌 전문가 모델.
- Flux Ultra: 선명한 4MP 생성으로 고해상도 출력을 최적화.
- Flux Raw: 포토리얼리즘에 집중하여 생생한 피부 질감, 조명, 사진적 디테일을 제공합니다.
- Flux Kontext (2025): 고급 워크플로우를 위한 컨텍스트 인식 편집 및 스마트한 장면 이해 기능을 도입.
Flux 2 개선 사항:
- 강력한 일관성: 다수의 주제 장면, 손, 세부 구성을 더 높은 정확도로 처리합니다.
- 더 선명한 출력 품질: Flux 1.1에 비해 향상된 텍스처, 조명 전환, 전체 충실도.
- 더 빠른 추론: 창의적 및 상업적 프로젝트 모두에서 더 빠른 반복 작업을 위한 최적화된 효율성.
- 더 나은 프롬프트 정렬: 드리프트가 줄어들고 설명적인 프롬프트에 대해 더 예측 가능한 반응을 제공합니다.
- Flux의 느낌 유지: Flux 1.1을 널리 인기 있게 만든 영화적이고 표현력 있는 미학을 유지합니다.

기타 인기 있는 Stable Diffusion 모델
새로운 모델들이 등장하는 가운데, 2024년과 2025년의 입증된 인기 모델들이 여전히 매우 중요한 역할을 하고 있습니다. RealVisXL과 AAM XL AnimeMix는 각자의 영역에서 지배적인 위치를 차지하고 있으며, Playground v2.5와 ThinkDiffusion XL은 예술적인 다양성과 기술적인 우수성을 제공합니다. 이 모델들은 안정적이고 신뢰할 수 있으며, 2026년에도 여전히 가치가 있습니다.
- RealVisXL V4.0: 사실감 있는 인간과 물체 렌더링을 위한 최고의 포토리얼리즘 XL 모델로 자리매김.
- AAM XL AnimeMix: 애니메이션 중심 모델로서 여전히 선두 자리를 지키고 있습니다.
- Playground v2.5: 예술적이고 창의적인 출력으로 찬사를 받은 모델.
- ThinkDiffusion XL: 선명한 4K 해상도 이미지를 생성하는 강력한 선택.
Stable Diffusion 결과 더욱 향상시키기
최고의 모델들도 이미지에서 노이즈, 블러 또는 압축 아티팩트를 생성할 수 있습니다. 전문가용 (예: 인쇄, 제품 이미지 또는 포트폴리오) 출력물을 향상시키고 싶다면, 이미지를 4K 이상으로 업스케일하거나 노이즈 및 블러를 제거하고 세밀한 디테일을 복구할 수 있습니다. 이때 Aiarty Image Enhancer가 최종 결과를 크게 향상시킬 수 있습니다.
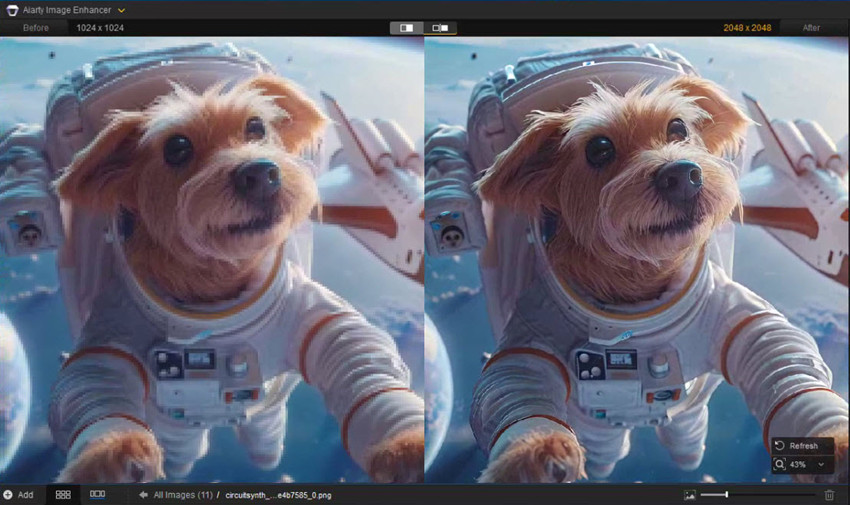
40+ Stable Diffusion 모델 목록
최고의 모델을 넘어 더 다양한 Stable Diffusion 모델을 탐색하고 싶다면, 스타일별로 분류된 모델 목록을 확인해 보세요.
팁: 모든 모델을 시도하는 대신, 2–3개의 핵심 모델(SDXL + 하나의 특화된 모델)로 시작하고 LoRA를 사용해 확장하세요.
| 이미지 스타일 | 모델 이름 | 모델 유형 | 기본 모델 |
|---|---|---|---|
| 리얼리스틱: 제품 | SDXL 제품 샷 | LORA | SDXL 1.0 |
| 리얼리스틱: 사람 | ChilloutMix | LORA | SD 1.5 |
| 리얼리스틱: 풍경/동물 | NextPhoto | 체크포인트 | SD 1.5 |
| 리얼리스틱: 게임/건축 | RealVisXL | 체크포인트 | SDXL 1.0 |
| 리얼리스틱: 야경 | NightVisionXL | 체크포인트 | SDXL 1.0 |
| 리얼리스틱: 음식 | Food Photography | LORA | SD 1.5 |
| 리얼리스틱: 패션 | Modern Vision | 체크포인트 | SD 1.5 |
| 인물 사진 | Modelshoot | 체크포인트 | SD 1.5 |
| 만화 | MANGA (일반) | LORA | SD 1.5 |
| 애니메이션 아트 | VaporWaveV1 | LORA | SD 1.5 |
| 만화 스타일 | ToonYou | 체크포인트 | SD 1.5 |
| 만화책 | Comic Diffusion | 체크포인트 | SD 1.5 |
| 픽셀 아트 | Pixel Art XL | LORA | SDXL 1.0 |
| 일러스트레이션 | Vector Art | 체크포인트 | SD 2.1 |
| 미래지향적 | Futuristic XL | LORA | SDXL 1.0 |
| 사이버펑크 | CyberpunkAI | LORA | SD 1.5 |
| 공상과학 | Sci-fi XL Style | LORA | SD 1.5 |
| 초현실주의 | ColorfulSurrealismAI | 체크포인트 | SD 1.5 |
| 복고풍 | RetroMix | 체크포인트 | SD 1.5 |
| 빈티지 | PhotoVintageV1.5 | 체크포인트 | SD 1.5 |
| 유화 | Oil Painting | LORA | SD 1.5 |
| 수채화 | Watercolor | LORA | SD 1.5 |
| 연필 드로잉 | Pencil Drawing | LORA | SDXL 1.0 |
| 그래피티 | Flonix’s Vector Style | 체크포인트 | SDXL 1.5 |
| 캐리커쳐 | Krueger Caricature Style XL | LORA | SDXL 1.0 |
| 영화적 | Juggernaut Cinematic XL | LORA | SDXL 1.0 |
| 보케 | Copax Bokeh | LORA | SD 1.5 |
| 3D 스타일 | 3D Rendering Style | LORA | SD 1.5 |
| 인테리어 디자인 | InteriorDesignSuperMix | 체크포인트 | SD 1.5 |
| 아르 데코 | Art Deco Fusion | LORA | SD 1.5 |
| 플랫 디자인 | Lineart Flat Colors | LORA | SD 1.5 |
| 로우 폴리 | Low Poly | LORA | SDXL 1.0 |
| 선화 | Niji Lineart | LORA | SD 1.5 |
| 벡터 아트 | vector-art | 체크포인트 | SD 2.1 |
| 고딕 | GothicpunkAI | LORA | SD 1.5 |
| 건축 | ArchitectureRealMix | 체크포인트 | SD 1.5 |
| 표현주의 | Paragon | 체크포인트 | SD 1.5 |
| 르네상스 | Renaissance XL | LORA | SDXL 1.0 |
| 종이 컷 | Papercut SDXL | LORA | SDXL 1.0 |
| 실루엣 | Silhouette | LORA | SD 1.5 |
| 형광 | Fluorescent Green | LORA | SD 1.5 |
| 무지갯빛 | Made Of Iridescent Foil | LORA | SD 2.1 |
Stable Diffusion의 최고의 모델을 어디에서 찾을 수 있나요?
Stable Diffusion을 탐색할 때, 좋은 모델을 어디서 찾을 수 있는지 아는 것이 시간을 절약하고 창작물을 향상시킬 수 있습니다. 최고의 소스는 다음과 같습니다:
- Civitai: Stable Diffusion 모델을 위한 주요 커뮤니티 허브입니다. 체크포인트, LoRA, 텍스트 인버전 모델 등 다양한 모델을 찾을 수 있습니다. civitai.com에 방문하여 모델 섹션으로 이동한 후, 모델 이름, 유형, 기본 모델 또는 상태별로 필터링하세요. 팁: 3~5개의 핵심 모델을 고수하고, LoRA를 사용해 세부 조정을 실험해보세요.
- Hugging Face: 공식 체크포인트와 실험적인 릴리스를 제공하며, 새로운 모델이나 첨단 모델을 탐색하기에 좋은 선택입니다.
- Stability AI: 공식 SDXL과 SD 3.0/3.5 릴리스를 제공하여 신뢰할 수 있는 성능과 호환성을 보장합니다.
- Ikomia / AI 블로그: 모델 간 비교, 벤치마크, 그리고 다양한 모델의 실제 성능에 대한 통찰을 얻기에 이상적입니다.
 Stable Diffusion 모델에 대한 자주 묻는 질문(FAQs)
Stable Diffusion 모델에 대한 자주 묻는 질문(FAQs)
현재 가장 강력한 Stable Diffusion 모델은 SD 3.5 Large, Flux 2, Z-image입니다. SD 3.5 Large는 최고 수준의 전체적인 충실도를 제공하고, Flux 2는 최고의 영화적이고 일관된 출력물을, Z-image는 빠르고 고품질의 생성과 강력한 사실감을 제공합니다. "최고의" 선택은 정확성, 스타일 제어 또는 속도 중 무엇을 우선시하는지에 따라 다릅니다.
Realistic Vision은 Stable Diffusion에서 가장 좋은 현실적인 모델입니다. 특히 진짜 얼굴과 눈을 가진 현실적인 인간을 생성하는 데 뛰어납니다.
Anything V5는 애니메이션 스타일이나 만화 같은 외모의 캐릭터와 풍경을 생성하는 데 가장 좋은 Stable Diffusion 애니메이션 모델입니다. 그러나 주로 일본 장르에 특화된 장면을 생성하는 데 집중합니다. 더 많은 Stable Diffusion 애니메이션 모델 보기 >>
Stable Diffusion은 "확산 모델"이라고 알려진 AI 모델을 사용하며, 특히 LMU 뮌헨의 CompVis 그룹에서 개발한 Latent Diffusion Model(LDM)을 사용합니다. 이 모델은 고품질 이미지 합성을 위해 설계되었으며 생성 모델의 일종입니다.
Stable Diffusion 모델을 얻을 수 있는 주요 사이트는 Civitai와 Hugging Face가 있습니다.
윤지훈은 10년 이상의 경력을 가진 숙련된 콘텐츠 제작자로, 멀티미디어 산업에서 활동해왔습니다. 그는 특히 AI 기반 이미지 편집 분야에서 심층적인 제품 리뷰와 실용적인 가이드를 전문으로 합니다. 기술 트렌드와 소셜 플랫폼에 대한 깊은 이해를 바탕으로 타겟에 맞춘 매력적인 콘텐츠를 창작합니다. 그의 스타일은 정교하면서도 생동감 있어 많은 독자들에게 사랑받고 있습니다.