Summary: This blog reviews the 8 best open source AI video generators, comparing their features, strengths, and limitations for creators and researchers. While these tools offer impressive customization and innovation, many struggle with low resolution and short video length. To overcome these challenges, highly recommending Aiarty Video Enhancer, which uses advanced AI to upscale, denoise, and stabilize AI-generated videos-transforming basic clips into polished, high-quality results with ease.
Compared to the commercial ones, open source AI video generators stand out by offering powerful, customizable tools at no cost, fostering innovation and accessibility. But there are so many out there, which one should you start with?
In this blog post, we have researched and tested the top open source AI video generators, highlighting their features, capabilities, and how they can help you bring your creative visions to life, for you. Whether you're crafting animations, marketing content, or experimental art, these tools are reshaping the future of video production.
Open source AI video generators often fall short in delivering high-resolution, long-duration videos with clear, professional-quality visuals. Users frequently struggle with low output resolution-rarely reaching 4K-and issues like noise, blurriness, and unstable frames that diminish the viewing experience.
Boost Your AI Video Quality with Aiarty Video Enhancer
Don't settle for blurry, low-res AI-generated videos. Aiarty Video Enhancer is your ultimate solution to enhance and upscale open source AI video outputs effortlessly. It can:
- Upscaling: Upscale lower-resolution AI-generated videos to higher resolutions like 4K, which can improve their clarity and sharpness on modern displays.
- Denoising: Reduce noise and artifacts that can be present in AI-generated videos, leading to cleaner and smoother visuals. Aiarty uses advanced denoising models like "superVideo vHQ" to handle challenging situations, such as low-light scenes, where noise is particularly prevalent.
- Deblurring and Sharpening: Enhance blurry or soft areas in AI-generated videos, improving their overall sharpness and detail. The "moDetail-HQ v2" model is especially effective for recovering fine textures like hair, skin, and natural elements, which can be useful when enhancing AI-generated portraits or nature scenes.
- Detail Generation and Preservation: Aiarty's AI models are trained to reconstruct realistic and natural details in your videos. This helps prevent the artificial or overly smooth look that can sometimes occur with AI video generation, especially when dealing with fine textures.
- Frame Interpolation: Create smoother motion in AI-generated videos by generating new frames, which is particularly useful for achieving smooth slow-motion effects.
Try Aiarty Video Enhancer today and elevate your AI video creations to a whole new level.
Download Aiarty Video Enhancer and make the AI videos sharper and smoother now!
8 Best Open Source AI Video Generators
1. Genmo Mochi 1
Genmo Mochi 1 is a leading open-source AI video generation model that sets a new benchmark in the field due to its scale, motion quality, and prompt fidelity. Developed by Genmo AI, it features a massive 10 billion parameter architecture based on the novel Asymmetric Diffusion Transformer (AsymmDiT), making it the largest publicly available video generation model.

Key Features of Genmo Mochi
- High-Fidelity Motion: Mochi 1 excels at producing smooth, realistic motion at 30 frames per second, simulating complex physical phenomena such as fluid dynamics, fur, and hair movement. This results in lifelike and temporally coherent videos that stand out among open-source models.
- Strong Prompt Adherence: The model demonstrates exceptional alignment with textual prompts, enabling precise control over characters, scenes, and actions when instructions are clear and detailed. This reduces the typical "daydreaming" or drifting seen in many generative models.
- Efficient Architecture: The AsymmDiT architecture processes text and video tokens separately, dedicating more parameters to visual processing for enhanced video quality while maintaining computational efficiency. The model uses a video VAE that compresses videos by a factor of 12 in latent space, enabling manageable memory use despite the large parameter count.
- Video Specifications: Currently, Mochi 1 generates videos at 480p resolution for up to about 5.4 seconds. An HD version (720p) with improved fidelity and smoother motion is planned for release within the year.
Limitations and Considerations
- Resolution and Length: The base model is limited to 480p resolution and short clips (~5 seconds), which may restrict use cases requiring longer or higher-resolution videos. However, the upcoming HD model aims to address this.
- Occasional Distortions: While motion is generally realistic, extreme or fast-paced actions can sometimes cause distortions or deformations in the generated videos.
- Hardware Requirements: Running Mochi 1 locally requires substantial GPU memory (typically high-end GPUs), which may limit accessibility for some users.
Mochi 1 is well-suited for researchers, developers, and creators seeking a powerful, open-source tool for generating photorealistic videos and even uncensored video clips from text prompts. Its ability to simulate natural physics and adhere closely to instructions makes it ideal for content creation, prototyping, and AI research.
2. Rhymes Allegro
Rhymes Allegro is a powerful open-source text-to-video AI model developed by Rhymes AI, capable of generating high-quality videos up to 6 seconds long at 720p resolution and 15 frames per second from simple text prompts. It uses advanced core technologies including:
- A Video Variational Autoencoder (VideoVAE) that compresses raw videos into smaller visual tokens while retaining essential details for smoother and more efficient generation.
- An extended diffusion Transformer architecture (VideoDiT) with 3D rotary positional embeddings and full 3D attention, enabling simultaneous spatial and temporal modeling of video frames for realistic motion and context.

Allegro's backbone is based on the DiT (Diffusion Transformer) architecture, which scales better than traditional UNet-based diffusion models, allowing it to capture nuanced motion and scene details effectively.
The model supports multiple precisions (FP32, BF16, FP16), with BF16 mode requiring only about 9.3GB GPU memory, making it relatively accessible for high-quality video generation. It can generate 6-second videos in roughly 20 minutes on a single NVIDIA H100 GPU, or in about 3 minutes using 8 H100 GPUs, demonstrating good efficiency for research and creative workflows.
Allegro currently focuses on text-to-video generation but is actively being developed to include image-to-video, motion control, and longer narrative/storyboard-style video generation capabilities. The project is fully open source under the Apache 2.0 license, with code and model weights available on GitHub and Hugging Face, encouraging community collaboration and commercial use.
In comparative tests, Allegro tends to handle facial expressions and stylistic details better than some other open-source models, though it may struggle more with complex scene compositions or high-action sequences compared to Genmo Mochi 1. It excels at producing smooth, expressive characters and cinematic visuals at 720p, making it a strong choice for creators prioritizing video quality and prompt fidelity in short clips.
3. Open-Sora
Open-Sora is an open-source AI video generation framework designed to democratize efficient, high-quality video production by making advanced video generation accessible to the public. It is distinct from OpenAI's proprietary video model named Sora, though they share a similar name.
Learn How to Use Sora and Get Sora 2 Invite Code >>
Key Features of Open-Sora
- Open Source and Cost-Effective: Open-Sora is fully open source with code and models available on GitHub under the Apache 2.0 license, enabling commercial use and community development. Its training cost is significantly lower than many comparable models (around $200,000), demonstrating efficiency in data curation, architecture, and training strategies.
- Architecture: Built on the Diffusion Transformer (DiT) architecture, Open-Sora incorporates a temporal attention layer added to a pre-trained text-to-image model (PixArt-α). It uses a pre-trained Video VAE encoder to compress video data into latent space, where the STDiT model jointly learns video and text features. This enables bidirectional flow of information between text and image tokens, improving generation quality.
- Multi-Stage Training Pipeline:
- Stage 1: Text-to-video generation at 256×256 resolution.
- Stage 2: Image-to-video generation, focusing on motion by conditioning on an initial image.
- Stage 3: High-resolution video generation (up to 768×768) using a Video Deep Compression Autoencoder to reduce computational load while preserving quality.
- Video Quality and Length: Supports generating videos up to 128 frames (~4-5 seconds) at resolutions from 256×256 to 768×768 pixels. It excels especially in image-to-video tasks, preserving content, structure, and style while adding smooth motion.
Comparison with OpenAI's Sora
- OpenAI's Sora is a commercial, subscription-based service integrated with ChatGPT Plus and Pro, offering up to 1080p resolution and 20-second videos with advanced editing tools like Remix and Storyboard.
- Open-Sora is a community-driven open-source model focusing on efficient training and local use, with somewhat lower resolution and video length but strong prompt adherence and motion quality.
- OpenAI's Sora is currently not fully publicly available worldwide, whereas Open-Sora is fully open and modifiable.
4. VideoCrafter
VideoCrafter is an open-source AI video generation and editing toolbox developed by the AI Lab CVC team that supports versatile video synthesis modes including text-to-video (T2V) and image-to-video (I2V). It enables the creation of cinematic-quality videos with resolutions up to 1024×576 and beyond, making it a flexible tool for both research and creative applications.
Key Features of VideoCrafter
- Multi-Modal Generation: Supports text-to-video, image-to-video, and video continuation within a unified framework, allowing users to generate videos from text prompts, animate images, or extend existing videos smoothly.
- Diffusion-Based Models: Uses diffusion techniques to preserve content, structure, and style, especially excelling in image-to-video tasks by adding natural motion while maintaining the original image's details.
- High-Quality Output: Capable of producing cinematic videos with good spatial and temporal coherence, suitable for storytelling and creative projects.
- Customizable Parameters: Allows users to adjust resolution, frame rate, and generation steps to balance video quality and generation speed.
Limitations: Some users note occasional choppiness or artifacts in longer videos, and video length is generally short, but ongoing research aims to improve these aspects.
5. CogVideoX
CogVideoX is a state-of-the-art, open-source AI video generation model developed by Tsinghua University and Zhipu AI, designed to generate high-quality videos from text prompts and images with strong controllability and versatility.

Key Features of CogVideoX
- Text-to-Video and Image-to-Video: CogVideoX supports both text-driven video generation and image-to-video conversion, allowing users to animate static images by adding motion and context, which is ideal for creative content, animation, and education.
- High-Quality Output: It generates videos up to 6 seconds long at 720×480 resolution and 8 frames per second, producing clear, detailed, and visually appealing videos suitable for professional use.
- Advanced Architecture: Utilizes a 3D Variational Autoencoder (3D VAE) that compresses video data across spatial and temporal dimensions, enabling efficient encoding and reconstruction. The model also includes an end-to-end video understanding component that improves adherence to complex and detailed prompts.
- Dual Model Options: Offers CogVideoX-5B for premium quality (requiring around 26GB GPU memory) and CogVideoX-2B for faster processing with lower memory demands (around 4GB), supporting multiple precisions such as FP16, BF16, and INT8.
- Additional Features: Supports video-to-video generation, multi-frame rate hierarchical training for smooth outputs, and the ability to generate longer videos by chaining frames or using keyframe-based generation.
Limitations
- Resolution and Frame Rate: Currently capped at 720×480 resolution and 8 FPS, which is lower than some commercial models but sufficient for many creative and research applications.
- Prompt Language: Primarily supports English input; users may need to translate other languages for best results.
- Hardware Requirements: High-quality generation (5B model) requires substantial GPU memory (~26GB), though the 2B variant is more accessible.
CogVideoX is well-suited for content creators, filmmakers, educators, and researchers who want to generate or animate videos from text and images with fine control and good visual fidelity. Its open-source nature and flexible architecture make it a strong candidate for experimentation, customization, and integration into creative pipelines.
6. Pyramid Flow
Pyramid Flow is a cutting-edge open-source AI video generation model developed by researchers from Peking University, Beijing University of Posts and Telecommunications, and Kuaishou Technology. It is designed to produce high-quality, coherent videos up to 10 seconds long at 768p resolution and 24 frames per second, making it one of the most advanced open-source video generators available.
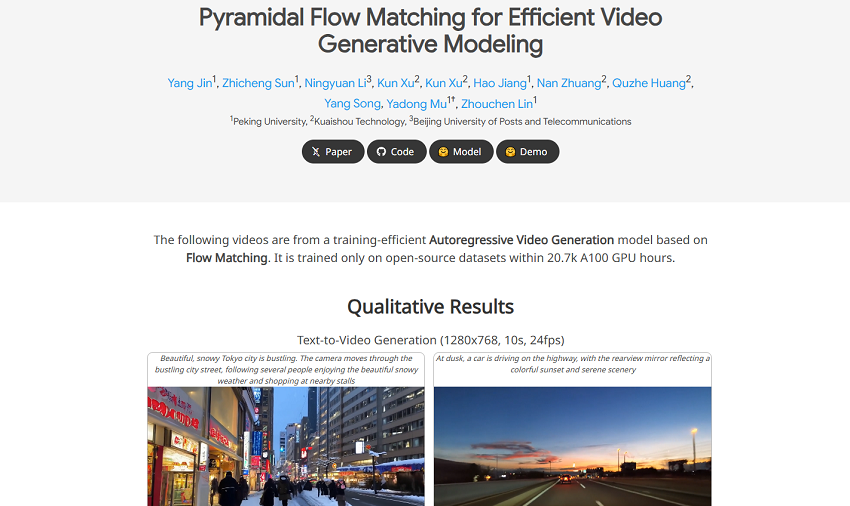
Key Features of Pyramid Flow
- Innovative Autoregressive Flow Matching Architecture: Pyramid Flow uses a novel autoregressive video generation method based on flow matching, which efficiently models spatial and temporal information. This approach significantly reduces computational costs by generating videos in a multi-stage "pyramid" process, where most stages operate at low resolution and only the final stage produces the full-resolution output.
- High-Resolution, Smooth Videos: It can generate 10-second videos at 768p and 24 FPS, delivering smooth motion and clear visuals suitable for professional and social media use.
- Strong Prompt Adherence: Employs a latent template-based defect contrastive localization technique to closely follow user input prompts, achieving output quality comparable to proprietary models like OpenAI Sora.
- Image-to-Video Support: Pyramid Flow naturally supports image-to-video conversion, allowing users to animate static images with smooth, natural motion.
- Training on Open Datasets: The model is trained exclusively on large-scale open-source datasets such as LAION-5B, WebVid-10M, and others, ensuring ethical AI development and diverse video content generation.
Limitations and Considerations
- Hardware Requirements: Generating high-resolution videos at 768p and 24 FPS requires powerful GPUs (e.g., NVIDIA A100) for efficient performance.
- Generation Time: Video generation can be time-consuming due to the model's complexity and high resolution, though it remains competitive with other open-source models.
7. Zeroscope
Zeroscope is an advanced open-source AI text-to-video generation model that transforms written descriptions into high-quality videos up to 1024×576 resolution without watermarks, positioning itself as a strong free alternative to commercial tools like Runway ML's Gen-2.
Key Features of Zeroscope
- High-Resolution Video Generation: Zeroscope offers a two-stage generation process. The initial model, Zeroscope_v2 567w, generates rapid drafts at 576×320 resolution for quick concept exploration. These drafts are then upscaled by Zeroscope_v2 XL to 1024×576 pixels, producing professional-quality, crisp, and vibrant videos.
- Diffusion-Based Architecture: Built on a multi-level diffusion model with 1.7 billion parameters, Zeroscope iteratively refines video content from noise guided by textual input. It leverages deep learning techniques including convolutional neural networks and attention mechanisms to capture complex spatial and temporal patterns, ensuring coherent and visually appealing video sequences.
- User-Friendly and Efficient: The platform offers intuitive controls for inputting text and selecting video styles, allowing users without advanced technical skills to generate videos quickly. The model is optimized for rapid content creation, enabling video generation in minutes, significantly reducing traditional production time.
- No Watermarks: Outputs are free of watermarks, making them suitable for professional use across various applications.
- Training and Dataset: Zeroscope was trained on nearly 10,000 video clips and almost 30,000 tagged frames, with noise augmentation techniques that improve its ability to generalize and generate diverse, realistic videos from varied textual prompts.
Limitations and Considerations
- Video Length and Frame Rate: Typically generates short clips (e.g., around 24 frames at 30 FPS), which is common among current open-source video generation models.
- Hardware Requirements: While the smaller model runs on many standard GPUs, the higher-resolution XL model requires more VRAM (around 15GB), which may limit accessibility for users with less powerful hardware.
- Early Stage Technology: As with most text-to-video AI models, Zeroscope videos may still exhibit some visual artifacts or inconsistencies, reflecting the early stage of video generation technology compared to mature text-to-image models.
8. SkyReels
SkyReels is an open-source, advanced AI video generation platform focused on producing high-quality, human-centric videos with cinematic aesthetics and natural motion. It supports both text-to-video (T2V) and image-to-video (I2V) generation, along with video editing and storytelling tools, making it a comprehensive solution for creators and researchers.
Key Features of SkyReels
- Human-Centric Video Generation: Trained on over 10 million high-quality film and TV clips, SkyReels captures 33 distinct facial expressions and over 400 natural motion combinations, enabling lifelike videos with professional lighting, camera effects, and scene consistency.
- Multi-Modal Support: Supports text-to-video, image-to-video, video-to-video extension, and elements-to-video generation, allowing versatile creative workflows including animating static images and extending existing videos.
- Long-Form Video Capability: SkyReels V2 introduces diffusion forcing models that break the typical 5-second video length barrier, enabling generation of ultra-smooth, coherent videos up to 28–30 seconds or longer without warping or frozen frames.
- Performance and Hardware: The model size is approximately 24GB, with recommended video memory of 16GB or above. On an RTX 4090, generating a 4-second video takes about 15 minutes on a single GPU, which can be reduced significantly with multi-GPU setups.
- Integrated Platform Features: SkyReels offers AI-powered voiceovers, lip-sync, sound effects, music, and video editing tools, streamlining the entire video creation process with one-click generation and an intuitive interface.
Comparison Table of Best Open Source AI Video Generators
| AI Video Generator | Architecture / AI Model | Video Quality / Resolution | Video Length Limits | Key Features / Use Cases | Hardware Requirements | Strengths | Limitations / Challenges |
|---|---|---|---|---|---|---|---|
| Genmo Mochi 1 | Custom AI / Diffusion-based | Low-to-Mid resolution | Short clips (seconds) | Creative animation, storytelling | GPU recommended | Easy to use, good for animation | Low resolution, short length |
| Rhymes Allegro | Transformer-based video model | Mid resolution | Very short videos | Music video generation, artistic content | High GPU needed | Strong for rhythm-synced videos | Limited length, noise in output |
| Open-Sora | Diffusion + GAN hybrid | Mid to High (up to 720p) | Medium length (up to 30s) | General purpose video creation | Mid-range GPU | Balanced quality and length | Stability issues, some blurriness |
| VideoCrafter | Open-source GAN video synthesis | Low to Mid resolution | Short clips | Quick prototyping, art projects | Low to mid GPU | Lightweight, fast generation | Artifacts and noise |
| CogVideoX | Large transformer model | Low to Mid resolution | About 10 seconds | Text-to-video generation | Very high GPU | State-of-the-art for text-guided video | Requires expensive hardware, noisy output |
| Pyramid Flow | Flow-based AI model | Mid resolution | Short to medium clips | Smooth motion and frame interpolation | Moderate GPU | Good motion continuity | Resolution capped |
| Zeroscope | Custom diffusion variant | High (up to 1080p) | Up to 1 minute | Marketing videos, product demos | High GPU | Higher resolution, longer clips | Requires optimization for speed |
| SkyReels | Hybrid diffusion + transformers | Mid resolution | Short clips | Animation, creative storytelling | Mid GPU | Versatile, customizable parameters | Some frame instability and noise |
Note:
Most tools struggle with balancing video length, resolution, and output quality due to computational limits and early stage technology.
Aiarty Video Enhancer is recommended as a post-processing tool to upscale, denoise, and smooth out AI-generated videos from any of these generators, greatly improving output quality.
Conclusion
Open source AI video generators have democratized video production, offering powerful, flexible tools that cater to creators of all skill levels. From generating dynamic animations to crafting professional-grade content, these platforms provide endless possibilities without the barrier of cost.
By leveraging the best open source options here, you can experiment, innovate, and bring your ideas to life with ease. As the open source community continues to evolve, these tools will only grow more sophisticated, making now the perfect time to dive in and explore their potential for your next creative project.
You May Also Like
This post was written by Brenda Peng who is a seasoned editor at Digiarty Software who loves turning ordinary photos into extraordinary works of art. With AI assistance from DeepSeek for brainstorming and drafting, the post is reviewed for accuracy by our expert Abby Poole for her expertise in this field.