Mejores modelos de Stable Diffusion (2026): Top 10 para realismo, anime y SDXL

Elegir el modelo correcto de Stable Diffusion puede mejorar o arruinar tus resultados al instante. Si estás generando rostros borrosos, estilos inconsistentes o pasando horas probando distintos checkpoints, el problema generalmente no es tu prompt, sino el propio modelo.
En 2026, varios modelos de Stable Diffusion destacan claramente: SDXL sigue siendo la mejor opción general y la más fácil para principiantes, mientras que Realistic Vision / RealVisXL sobresalen en imágenes fotorrealistas, Anything v5 / AAM XL son ideales para estilos anime, y Juggernaut XL ofrece resultados cinematográficos y de alto detalle.
Esta guía no es solo una lista larga — es un análisis probado y categorizado para ayudarte a encontrar rápidamente el mejor modelo de Stable Diffusion para tu caso de uso específico.
Si tienes poco tiempo y solo quieres lo más importante, aquí tienes un desglose rápido de los mejores modelos para probar. Cada categoría representa una opción destacada basada en rendimiento, estilo y feedback de la comunidad. El mejor modelo de Stable Diffusion depende de tu objetivo:
- Mejor en general: SDXL
- Mejor modelo todoterreno y enfocado en creadores: Z-Image (excelente para retratos, productos, arte estilizado y resultados listos para diseño gráfico)
- Mejor para realismo: Realistic Vision / RealVisXL V4.0
- Mejor para anime: Anything v5 / AAM XL AnimeMix
- Mejor para fantasía y ciencia ficción: DreamShaper
- Mejor para imágenes fotográficas y cinematográficas: Juggernaut XL v9
- Mejor modelo de alta resolución 4K: ThinkDiffusion XL (especialista comunitario en alta resolución)
- Mejor novedad 2026: SD 3.5 Large (la siguiente evolución después de SDXL)
- Mejor suite profesional versátil: Flux 1.1 Pro / Ultra / Raw
- Mejor arquitectura de nueva generación: Flux 2 (más estable, rápido y nítido en escenas complejas)
Si no estás seguro, comienza con SDXL y luego refina tus resultados usando modelos LoRA.
6 mejores modelos de Stable Diffusion de todos los tiempos
Si no estás seguro de qué modelo elegir, esta comparación rápida te ayudará:
| Modelo | Mejor para | Fortaleza | Debilidad |
|---|---|---|---|
| SDXL | Uso general | Versátil, salida de alta calidad en múltiples estilos | Débil en renderizado de texto |
| Z-Image | Uso general y generación rápida | Inferencia rápida, buena alineación con prompts, buen realismo | Ecosistema más pequeño, menos soporte de LoRA |
| Realistic Vision | Fotorrealismo | Excelentes rostros humanos y detalles realistas | Flexibilidad de estilo limitada |
| DreamShaper | Fantasía e ilustración | Fuerte estilo artístico, ideal para escenas sci-fi y creativas | Resultados menos realistas |
| Anything v5 | Anime | Fuerte estilo anime con visuales vibrantes | No apto para realismo |
| Juggernaut XL | Imágenes cinematográficas | Alto nivel de detalle, iluminación y composición cinematográfica | Alto consumo de recursos |
SDXL — Mejor modelo general de Stable Diffusion
Mejor para principiantes, creadores generales y cualquiera que quiera resultados fiables sin necesidad de sobreoptimización
Si solo quieres instalar un modelo, SDXL sigue siendo la opción más segura en 2026. Funciona de manera fiable en casi todos los casos de uso — desde retratos y fotos de productos hasta paisajes y arte estilizado — sin necesidad de prompts complejos o ajustes avanzados. Esto lo convierte en un punto de partida ideal para principiantes, aunque también es lo suficientemente potente para creadores experimentados.
Como modelo insignia de Stability AI, SDXL es conocido por su excepcional versatilidad y su capacidad para generar imágenes altamente detalladas y realistas en una amplia variedad de estilos, incluyendo realismo, anime e ilustración. Entrenado con imágenes de 1024×1024, ofrece una gran calidad y consistencia general. Sin embargo, aún tiene dificultades con la generación precisa de texto.
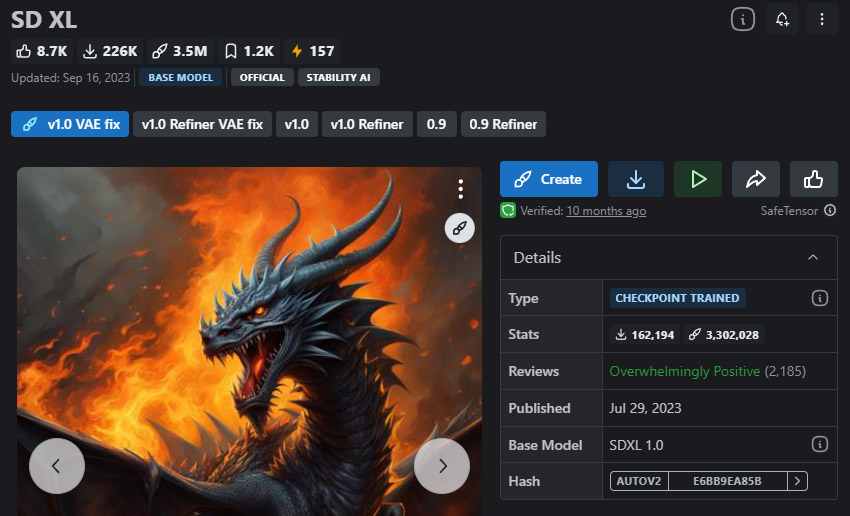
- Entrega imágenes de alta calidad de forma consistente a resolución 1024×1024.
- Gestiona estilos realistas y artísticos mejor que la mayoría de modelos.
- Fuerte soporte del ecosistema (LoRA, fine-tunes, herramientas).
- La generación de texto aún no es fiable.
- Requiere LoRAs compatibles con SDXL.
- ligeramente más pesado que los modelos antiguos SD 1.5.
Z-Image — Mejor modelo todoterreno para velocidad y calidad
Mejor modelo todoterreno y enfocado en creadores, impulsado por la nueva arquitectura S3-DiT para una generación de imágenes rápida y de alta calidad.
Z-Image es un modelo de nueva generación construido sobre el nuevo backbone S3-DiT (Transformador de Difusión de Flujo Único Escalable). A diferencia de las arquitecturas tradicionales de doble flujo, Z-image procesa las entradas de texto e imagen a través de una única ruta unificada desde el principio. Este diseño simplificado y altamente eficiente permite que el modelo funcione más rápido mientras mantiene una impresionante fidelidad visual.
Con solo 6 mil millones de parámetros, Z-image sigue siendo ligero pero sorprendentemente capaz, ofreciendo fotorealismo consistente, fuerte control estilístico y mejor rendimiento en la generación de texto que muchos modelos de tamaño similar. Es especialmente atractivo para creadores que producen retratos, fotos de productos, visuales estilizados y contenido listo para uso comercial sin necesidad de prompts complejos.
El modelo viene en tres variantes: Z-image Turbo, una versión rápida optimizada para inferencia de 8 pasos e ideal para GPUs de consumo como la RTX 4090; Z-image Base, la versión no destilada adecuada para fine-tuning y entrenamiento LoRA; y Z-image Edit, un modelo especializado diseñado para edición de imágenes basada en instrucciones.
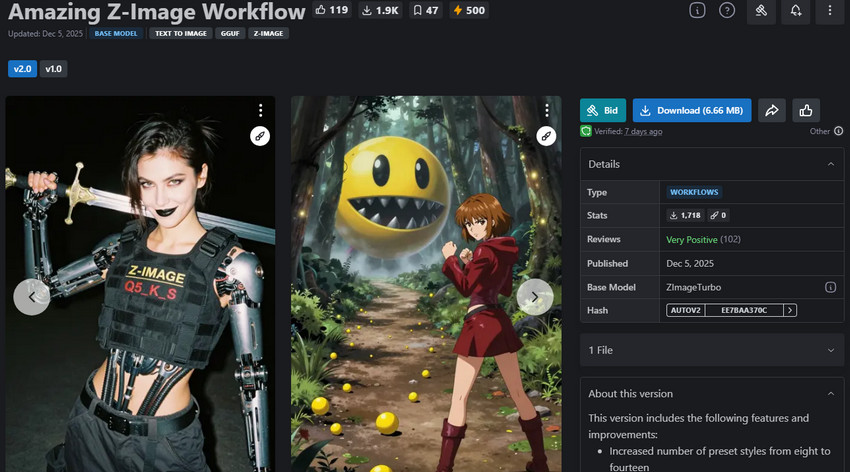
- Arquitectura S3-DiT eficiente con salida rápida y de alta calidad.
- Excelente para retratos, productos y visuales comerciales estilizados.
- Soporta múltiples variantes, incluyendo Turbo, Base y Edit.
- La generación de texto ha mejorado, pero aún no es totalmente fiable.
- Las poses de manos y escenas complejas con múltiples objetos pueden requerir ajustes.
- Ecosistema de LoRAs más pequeño en comparación con SDXL.
Realistic Vision — Mejor para imágenes fotorrealistas
Mejor para: retratos, fotos de productos, fotografía lifestyle y visuales comerciales
Si tu objetivo es generar imágenes que parezcan fotos reales, Realistic Vision es uno de los modelos más fiables disponibles. Destaca en la generación de tonos de piel naturales y detalles faciales, iluminación y sombras realistas, y texturas de ropa y detalles finos. En comparación con SDXL, produce humanos más realistas con menos esfuerzo en los prompts.
Pero también existen limitaciones a tener en cuenta, como no ser ideal para arte fantástico o estilizado, y tener menos flexibilidad entre distintos estilos.
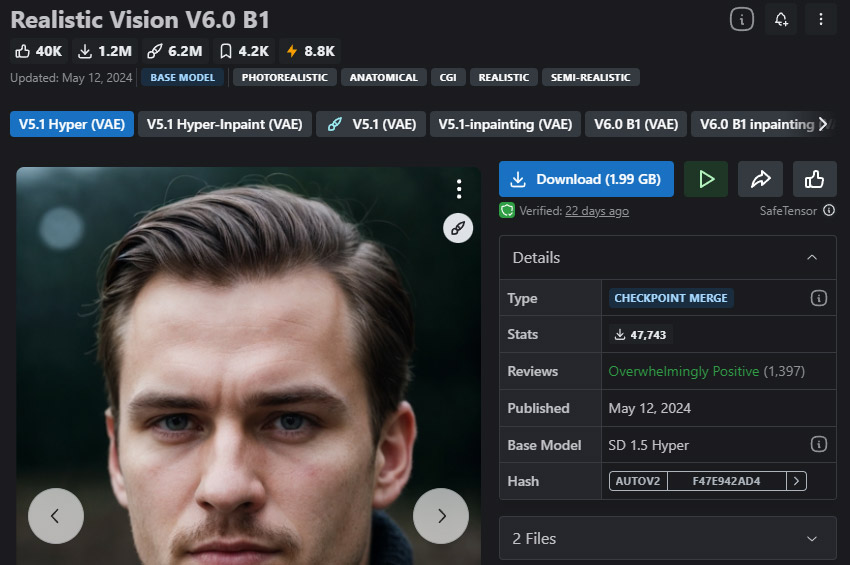
- Extremadamente adecuado para generar humanos realistas.
- Las imágenes generadas son altamente detalladas y muy realistas.
- Soporta NSFW.
- Versión de inpainting disponible.
- No puede generar entornos o imágenes de fantasía.
DreamShaper — Mejor para fantasía e ilustración
Mejor modelo de Stable Diffusion para mundos fantásticos, ilustraciones y escenas de ciencia ficción.
DreamShaper es la mejor opción para quienes buscan mundos excepcionales, como visuales de estilo sci-fi y cyberpunk. Con su diseño distintivo, busca dar vida a entornos místicos, criaturas mitológicas y paisajes fantásticos. DreamShaper está cuidadosamente diseñado para crear visuales similares a obras de arte, inspirándose en el anime con un estilo de pintura realista. Su impresionante capacidad radica en crear personajes en escenarios espectaculares.
Este modelo de Stable Diffusion es una excelente herramienta para crear imágenes que abarcan una amplia variedad de temas, desde representaciones realistas hasta composiciones creativas y oníricas, con seres únicos, animales, objetos, paisajes y más.
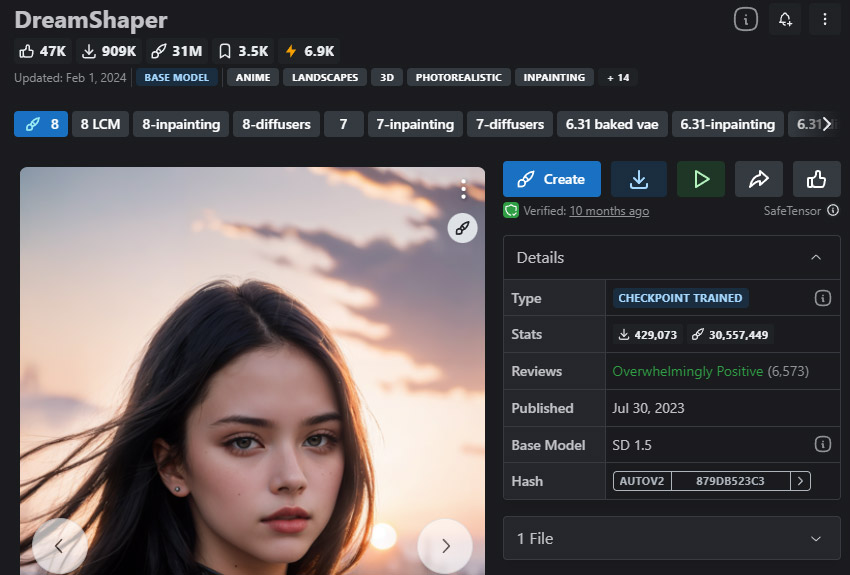
- Excelente para crear temas sci-fi y cyberpunk.
- Ideal tanto para fotorealismo como para estilos anime.
- Versión de inpainting disponible.
- Soporta NSFW.
- No es ideal para generar imágenes realistas.
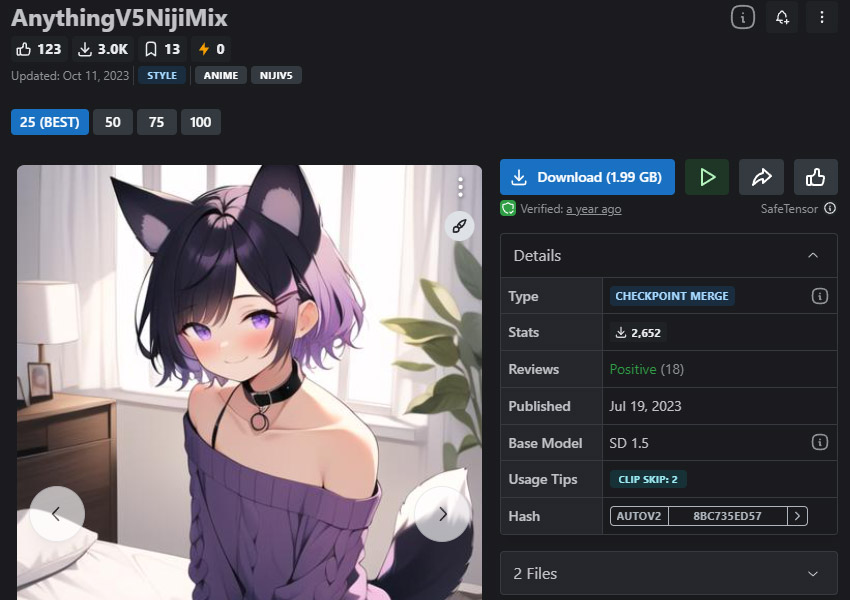
Anything v5 — Mejor para estilos anime
Mejor modelo de Stable Diffusion para estilos anime y apariencia tipo cartoon.
Anything v5 es un modelo personalizado de Stable Diffusion diseñado para crear visuales cautivadores que evocan la esencia de tu anime y manga favoritos. Espera colores vivos, personajes expresivos y composiciones dinámicas que dan vida al mundo del anime. En especial, este modelo está diseñado con la intención de recrear escenas comunes del anime japonés.
Anything v5 puede crear personajes y paisajes en estilo anime o ilustración. Cuando se trata de generar retratos, destaca en producir un protagonista juvenil con numerosos elementos de diseño detallados. A pesar de su apariencia animada, Anything es capaz de crear escenarios hermosos con una paleta de colores suave.
- Cubre muchos estilos de arte anime.
- Genera personajes y fondos anime con un toque realista.
- Crea imágenes totalmente coloridas con colores vibrantes.
- Genera formas y elementos complejos.
- Soporta NSFW.
- Tiende a generar personajes femeninos.
- Crea escenas típicas del género japonés.
- Requiere algo de experimentación con VAE.
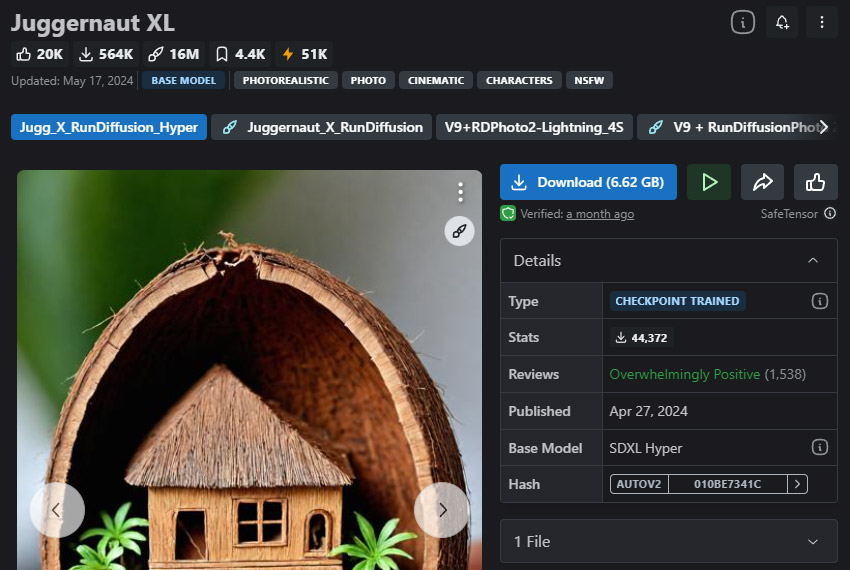
Juggernaut XL
Mejor modelo de Stable Diffusion para imágenes estilo fotografía/fotos reales.
Juggernaut XL es un sucesor excepcional del modelo SDXL para quienes buscan llevarlo al límite. La versión refinada ofrece mayor detalle y fidelidad, lo que lo hace perfecto para producir imágenes hiperrealistas que combinan arte digital con fotografía. Su notable capacidad para capturar detalles intrincados con gran claridad lo convierte en una herramienta invaluable para crear una amplia gama de sujetos, ya sean figuras humanas completas, objetos, logotipos o paisajes. Esto lo hace especialmente útil para retratos fotorrealistas o ilustraciones de moda que requieren un acabado único e incomparable.
Juggernaut XL ha sido mejorado con entrenamiento especializado en imágenes cinematográficas, elevando la calidad natural y cinematográfica de las imágenes resultantes. Para quienes buscan crear imágenes que capturen la esencia auténtica de fotografías reales, Juggernaut XL ofrece una experiencia inmersiva.
- Perfecto para fotos fotorrealistas y tomas con aspecto cinematográfico.
- Maneja variaciones de tamaño de imagen con facilidad.
- Compatible con modelos LoRA de SDXL.
- Soporta NSFW.
- Consume muchos recursos.
- No siempre es completamente fotorrealista.
- Curva de aprendizaje más pronunciada.
Modelos de Stable Diffusion que siguen liderando en 2026
Stable Diffusion continúa evolucionando, y 2026 ya ha introducido avances emocionantes. Desde versiones optimizadas para hardware hasta capacidades de edición de nueva generación, aquí tienes las actualizaciones más importantes que debes conocer.
Modelos LoRA (Low-Rank Adaptation)
Los modelos LoRA se han convertido en una parte esencial del ecosistema de Stable Diffusion. En lugar de reemplazar checkpoints base, los LoRA funcionan como complementos ligeros que inyectan estilos, personajes o conceptos específicos en modelos como SD 3.5 Large. Esto los hace ideales para creadores que buscan flexibilidad sin tener que gestionar múltiples modelos pesados.
Características clave de los modelos LoRA:
- Extensiones ligeras del modelo, normalmente de solo unos cientos de MB, en comparación con checkpoints base de varios GB.
- Diseñados para añadir o modificar elementos específicos como estilos artísticos, personajes, ropa o iluminación.
- Apilables y ajustables, lo que permite combinar múltiples LoRA con distintos valores de intensidad.
- Totalmente compatibles con modelos base modernos como SD 3.5 Large, SDXL y variantes afinadas.
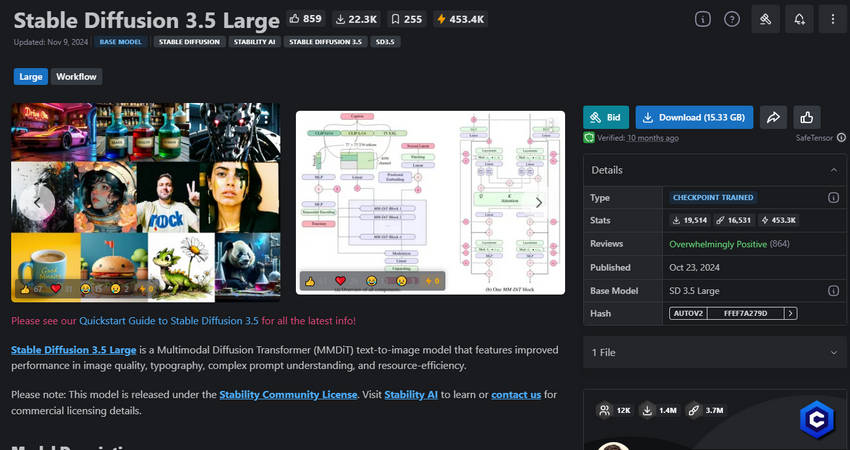
SD 3.5 Large
SD 3.5 Large representa un gran salto respecto a la serie 3.0, con un enfoque en la calidad y la versatilidad en múltiples estilos. Junto a él, SD 3.5 Medium ofrece una opción equilibrada para creadores cotidianos, mientras que SD 3.5 Large Turbo se centra en la velocidad, permitiendo iteraciones más rápidas con un nivel de detalle ligeramente menor. En conjunto, estas variantes hacen que la familia SD 3.5 sea adecuada para usuarios de todos los niveles, desde aficionados hasta profesionales de la industria.
Características clave de SD 3.5 Large:
- La versión insignia de la línea 2026 de Stability AI, entrenada con conjuntos de datos más amplios y optimizada para una fidelidad aún mayor.
- Genera imágenes con mayor precisión, detalle y rango estilístico que versiones anteriores.
- Diseñado para uso profesional, con fuerte soporte tanto para proyectos creativos como comerciales.
Serie Flux (Flux 1.1 → Flux 2)
La familia Flux representa una de las evoluciones más importantes en los modelos de difusión modernos, pasando de la popular serie Flux 1.1 a la más avanzada y estable Flux 2. Cada generación se centra en la expresividad creativa, el estilo cinematográfico y la flexibilidad de los prompts, mientras que Flux 2 introduce mejoras importantes en coherencia, calidad de detalle y velocidad. En conjunto, la línea Flux ofrece una amplia gama de opciones para artistas, diseñadores y creadores que buscan control consistente en diferentes estilos y resoluciones.
Serie Flux 1.1:
- Flux 1.1 Pro: Un modelo equilibrado y profesional diseñado para amplia cobertura de prompts y renderizado cinematográfico.
- Flux Ultra: Optimizado para salida en alta resolución con generaciones nítidas en 4MP.
- Flux Raw: Enfocado en el fotorrealismo, ofreciendo texturas de piel, iluminación y detalle fotográfico muy realistas.
- Flux Kontext (2026): Introduce edición consciente del contexto y una comprensión de escenas más inteligente para flujos de trabajo avanzados.
Mejoras de Flux 2:
- Mayor coherencia: Maneja escenas con múltiples sujetos, manos y composiciones detalladas con mayor precisión.
- Mayor nitidez en la salida: Texturas mejoradas, transiciones de iluminación y fidelidad general superior en comparación con Flux 1.1.
- Inferencia más rápida: Eficiencia optimizada para iteraciones más rápidas en proyectos creativos y comerciales.
- Mejor alineación con prompts: Menor desviación y respuestas más predecibles a descripciones detalladas.
- Mantiene el estilo Flux: Conserva la estética cinematográfica y expresiva que hizo popular a Flux 1.1.

Más modelos favoritos de Stable Diffusion
Incluso cuando llegan nuevos modelos, los favoritos probados de 2024 y 2025 siguen siendo muy relevantes. RealVisXL y AAM XL AnimeMix dominan sus nichos, mientras que Playground v2.5 y ThinkDiffusion XL ofrecen variedad artística y excelencia técnica. Son estables, confiables y aún valen la pena en 2026.
- RealVisXL V4.0: sigue siendo un modelo XL líder en realismo para renderizado de humanos y objetos fotorrealistas.
- AAM XL AnimeMix: continúa siendo el modelo líder en anime.
- Playground v2.5: reconocido por sus resultados altamente artísticos y creativos.
- ThinkDiffusion XL: una excelente opción para generar imágenes nítidas en resolución 4K.
Mejora aún más tus resultados de Stable Diffusion
Incluso los mejores modelos pueden generar imágenes con ruido, desenfoque o artefactos de compresión. Si quieres mejorar tus resultados para uso profesional (por ejemplo, impresión, imágenes de producto o portafolios), puedes escalar imágenes a 4K o más, eliminar ruido y desenfoque, y recuperar detalles finos. Aquí es donde Aiarty Image Enhancer puede mejorar significativamente tus resultados finales.
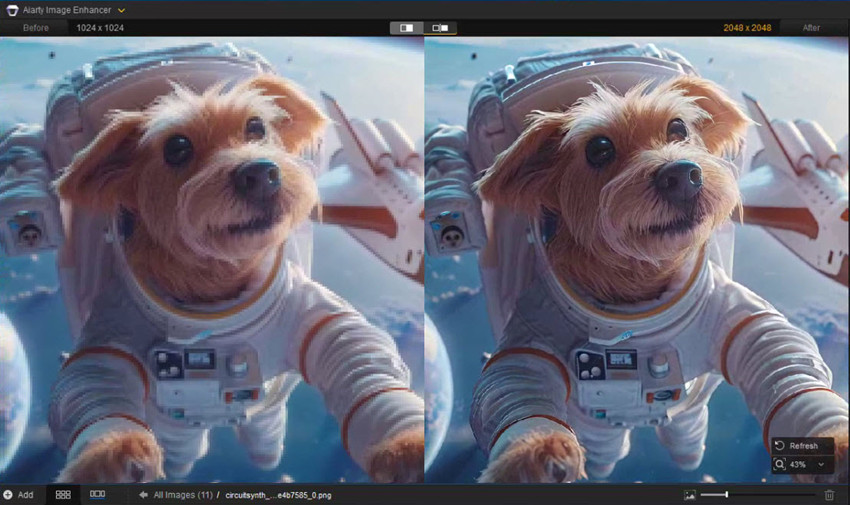
Lista de 40+ modelos de Stable Diffusion
Si quieres explorar más allá de las mejores opciones, aquí tienes una lista más amplia de modelos de Stable Diffusion categorizados por estilo.
Consejo: En lugar de probar todo, empieza con 2–3 modelos principales (como SDXL + un modelo especializado) y amplía con LoRAs.
| Estilo de imagen | Nombre del modelo | Tipo de modelo | Modelo base |
|---|---|---|---|
| Realista: Producto | SDXL Product Shot | LORA | SDXL 1.0 |
| Realista: Humanos | ChilloutMix | LORA | SD 1.5 |
| Realista: Paisajes/Animales | NextPhoto | Checkpoint | SD 1.5 |
| Realista: Juegos/Arquitectura | RealVisXL | Checkpoint | SDXL 1.0 |
| Realista: Nocturno | NightVisionXL | Checkpoint | SDXL 1.0 |
| Realista: Comida | Food Photography | LORA | SD 1.5 |
| Realista: Moda | Modern Vision | Checkpoint | SD 1.5 |
| Retratos | Modelshoot | Checkpoint | SD 1.5 |
| Manga | MANGA (General) | LORA | SD 1.5 |
| Anime | VaporWaveV1 | LORA | SD 1.5 |
| Cartoon | ToonYou | Checkpoint | SD 1.5 |
| Cómic | Comic Diffusion | Checkpoint | SD 1.5 |
| Pixel Art | Pixel Art XL | LORA | SDXL 1.0 |
| Ilustración | Vector Art | Checkpoint | SD 2.1 |
| Futurista | Futuristic XL | LORA | SDXL 1.0 |
| Ciberpunk | CyberpunkAI | LORA | SD 1.5 |
| Ciencia ficción | Sci-fi XL Style | LORA | SD 1.5 |
| Surrealismo | ColorfulSurrealismAI | Checkpoint | SD 1.5 |
| Retro | RetroMix | Checkpoint | SD 1.5 |
| Vintage | PhotoVintageV1.5 | Checkpoint | SD 1.5 |
| Óleo | Oil Painting | LORA | SD 1.5 |
| Acuarela | Watercolor | LORA | SD 1.5 |
| Dibujo a lápiz | Pencil Drawing | LORA | SDXL 1.0 |
| Grafiti | Flonix’s Vector Style | Checkpoint | SDXL 1.5 |
| Caricatura | Krueger Caricature Style XL | LORA | SDXL 1.0 |
| Cinemático | Juggernaut Cinematic XL | LORA | SDXL 1.0 |
| Bokeh | Copax Bokeh | LORA | SD 1.5 |
| Estilo 3D | 3D Rendering Style | LORA | SD 1.5 |
| Diseño de interiores | InteriorDesignSuperMix | Checkpoint | SD 1.5 |
| Art déco | Art Deco Fusion | LORA | SD 1.5 |
| Diseño plano | Lineart Flat Colors | LORA | SD 1.5 |
| Low Poly | Low Poly | LORA | SDXL 1.0 |
| Arte lineal | Niji Lineart | LORA | SD 1.5 |
| Arte vectorial | vector-art | Checkpoint | SD 2.1 |
| Gótico | GothicpunkAI | LORA | SD 1.5 |
| Arquitectura | ArchitectureRealMix | Checkpoint | SD 1.5 |
| Fauvismo | Paragon | Checkpoint | SD 1.5 |
| Renacimiento | Renaissance XL | LORA | SDXL 1.0 |
| Papel recortado | Papercut SDXL | LORA | SDXL 1.0 |
| Silueta | Silhouette | LORA | SD 1.5 |
| Fluorescente | Fluorescent Green | LORA | SD 1.5 |
| Iridescente | Made Of Iridescent Foil | LORA | SD 2.1 |
¿Dónde encontrar los mejores modelos para Stable Diffusion?
Al explorar Stable Diffusion, saber dónde encontrar modelos de calidad puede ahorrar tiempo y mejorar tus creaciones. Aquí tienes las principales fuentes:
- Civitai: El principal centro comunitario para modelos de Stable Diffusion. Puedes encontrar checkpoints, LoRAs, modelos de textual inversion y más. Simplemente visita civitai.com, ve a la sección de Modelos y filtra por nombre, tipo, modelo base o estado. Consejo: mantén 3–5 modelos principales para no abrumarte y usa LoRAs para ajustes finos.
- Hugging Face: Ofrece checkpoints oficiales y versiones experimentales, ideal para explorar modelos nuevos o de vanguardia.
- Stability AI: Proporciona los lanzamientos oficiales de SDXL y SD 3.0/3.5, garantizando rendimiento y compatibilidad fiables.
- Ikomia / Blogs de IA: Ideal para comparaciones lado a lado, benchmarks y análisis del rendimiento de distintos modelos.
 Preguntas frecuentes sobre modelos de Stable Diffusion
Preguntas frecuentes sobre modelos de Stable Diffusion
Actualmente, los modelos de Stable Diffusion más potentes son SD 3.5 Large, Flux 2 y Z-image. SD 3.5 Large ofrece la mayor fidelidad general, Flux 2 proporciona los mejores resultados cinematográficos y coherentes, y Z-image permite una generación rápida y de alta calidad con gran realismo. La “mejor” opción depende de si priorizas precisión, control de estilo o velocidad.
Realistic Vision es el mejor modelo realista para Stable Diffusion. Es especialmente bueno generando humanos realistas con rostros y ojos naturales.
Anything V5 es el mejor modelo de anime de Stable Diffusion para crear personajes y paisajes con estilo anime o apariencia de dibujo animado. Sin embargo, se centra en escenas típicas del género japonés. Ver más modelos de anime de Stable Diffusion >>
Stable Diffusion utiliza un tipo de modelo de IA conocido como “modelo de difusión”, específicamente un Modelo de Difusión Latente (LDM) desarrollado por el grupo CompVis de la LMU Múnich. Este modelo está diseñado para la síntesis de imágenes de alta calidad y forma parte de la familia de modelos generativos.
Hay dos lugares principales para obtener modelos de Stable Diffusion, incluyendo Civitai y Hugging Face.
También te puede gustar
Con una década de experiencia en edición de imágenes con IA, Rob Jonson se especializa en reseñas de software y guías prácticas. Su conocimiento de las tendencias tecnológicas y redes sociales le permite crear contenido atractivo para una amplia audiencia.