最佳 Stable Diffusion 模型(2026):写实、动漫等场景的首选推荐
选择合适的 Stable Diffusion 模型,往往直接决定了最终成品的成败。
如果你生成的人脸模糊、风格不一致,问题通常不在于你的提示词,而在于模型本身。
在 2026 年,几款 Stable Diffusion 模型脱颖而出:SDXL 依然是综合表现最佳且对新手最友好的选择;Realistic Vision / RealVisXL 在写实图像方面表现出色;Anything v5 / AAM XL 是动漫风格的首选;而 Juggernaut XL 则能生成电影级的高细节图像。
本指南并非简单罗列,而是一份经过实测的分类整理,旨在帮助你根据具体需求,快速找到最适合的 Stable Diffusion 模型。
如果你时间有限,只想快速了解重点,以下是几款值得尝试的头部模型,按性能、风格和社区反馈进行区分。最佳 Stable Diffusion 模型取决于你的目标:
- 综合最佳:SDXL
- 全能 & 创作者首选:Z-Image(在人像、产品、风格化艺术及可直接输出的图形上表现出色)
- 最佳写实:Realistic Vision / RealVisXL V4.0
- 最佳动漫:Anything v5 / AAM XL AnimeMix
- 最佳奇幻 & 科幻:DreamShaper
- 最佳摄影 & 电影感:Juggernaut XL v9
- 最佳 4K / 高分辨率模型:ThinkDiffusion XL(社区训练的高分辨率专家模型)
- 2025 年最佳新秀:SD 3.5 Large(SDXL 之后的新一代进化版)
- 最佳全能专业套件:Flux 1.1 Pro / Ultra / Raw
- 最佳下一代架构:Flux 2(在复杂场景下更稳定、更快、更锐利)
如果不确定如何选择,建议从 SDXL 开始,再通过 LoRA 模型进行精细化调整。
史上 6 款最值得推荐的 Stable Diffusion 模型
如果你不确定该选哪个模型,以下快速对比可以帮助你做出决定:
| 模型 | 适用场景 | 优势 | 不足 |
|---|---|---|---|
| SDXL | 全能 | 跨风格通用性强,输出质量高 | 文字渲染能力较弱 |
| Z-Image | 全能 & 快速生成 | 推理速度快,提示词响应强,写实效果出色 | 生态较小,LoRA 支持相对较少 |
| Realistic Vision | 写实风格 | 人脸和细节表现优秀 | 风格灵活性有限 |
| DreamShaper | 奇幻 & 插画 | 艺术风格强烈,适合科幻及创意场景 | 写实输出能力较弱 |
| Anything v5 | 动漫 | 动漫风格成熟,画面鲜艳 | 不适合写实风格 |
| Juggernaut XL | 电影级图像 | 细节丰富,电影级光影与构图 | 资源消耗较大 |
SDXL —— 综合表现最佳的选择
适合初学者、一般创作者,以及希望在不进行过度调优的前提下获得稳定输出结果的用户
如果你只想安装一个模型,SDXL 在 2026 年仍然是最稳妥的选择。无论人像、产品拍摄、风景还是风格化艺术,几乎所有场景下它都能稳定输出,无需复杂提示词或大量调试。这使得它成为初学者的理想起点,同时对经验丰富的创作者也足够强大。
作为 Stability AI 的旗舰模型,SDXL 以其卓越的全能性著称,能够在写实、动漫和插画等多种风格中生成高度细腻、逼真的图像。SDXL 基于 1024×1024 分辨率训练,整体画质和一致性表现出色,但文字渲染仍然不够理想。
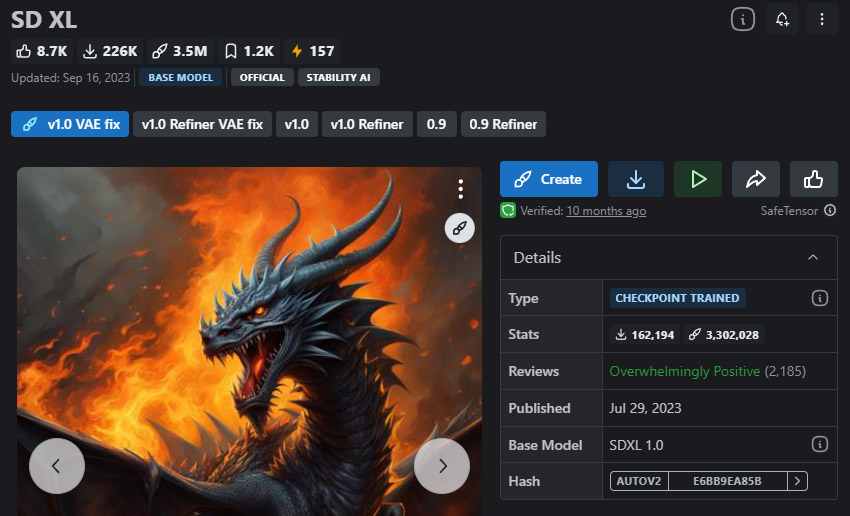
- 在 1024×1024 分辨率下输出质量稳定且高。
- 相比大多数模型,在写实和艺术风格之间切换自如。
- 生态系统完善(LoRA、微调模型、工具支持)。
- 文字生成仍然不够可靠。
- 需要使用兼容 SDXL 的 LoRA。
- 相比早期 SD 1.5 模型,资源消耗稍高。
Z-Image — 全能型首选:速度与画质的平衡之选
全能型 & 创作者首选模型,基于全新 S3-DiT 架构,实现快速、高质量的图像生成。
Z-Image 是一款基于新一代 S3-DiT(可扩展单流扩散 Transformer)架构构建的模型。与传统的双流架构不同,Z-Image 从一开始就通过统一的单通道处理文本和图像输入。这种简化且高效的设计使模型能够运行更快,同时保持令人印象深刻的视觉保真度。
Z-Image 仅拥有 60 亿参数,轻量但能力出众,能持续生成出色的写实图像,具备强大的风格控制能力,文字渲染表现也优于许多同尺寸模型。它尤其适合需要生成人像、产品图、风格化视觉以及可直接用于商业内容的创作者,且无需使用复杂的提示词。
该模型有三个变体版本:Z-Image Turbo,专为 8 步推理优化的快速版,非常适合 RTX 4090 等消费级 GPU;Z-Image Base,非蒸馏版基础模型,适合微调和 LoRA 训练;以及 Z-Image Edit,专为基于指令的图像编辑而设计的模型。
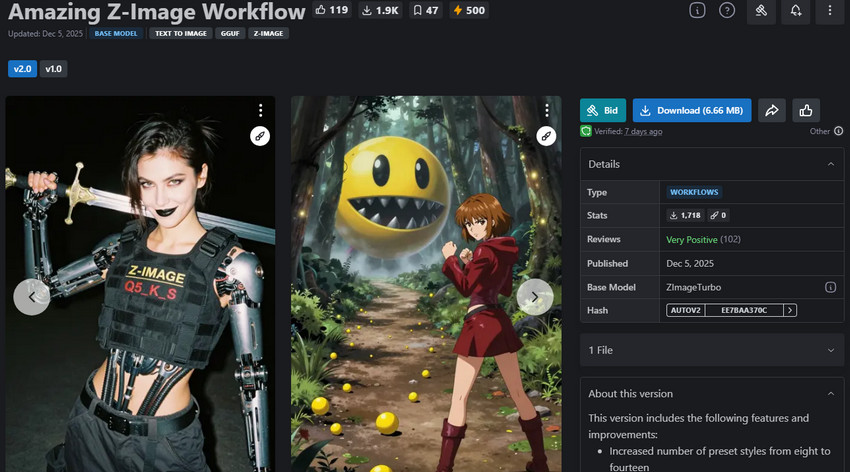
- 高效的 S3-DiT 架构,输出速度快、画质高。
- 在人像、产品图、风格化商业视觉方面表现出色。
- 支持 Turbo、Base、Edit 等多个变体版本。
- 文字渲染有改善,但仍不够稳定可靠。
- 手部姿态和复杂多物体场景可能需要额外优化。
- LoRA 生态相比 SDXL 较小。
Realistic Vision — 写实风格图像的最佳选择
适用场景:人像、产品摄影、生活照、商业视觉素材
如果你的目标是生成看起来像真实照片的图像,Realistic Vision 是目前最可靠的模型之一。它擅长渲染自然的肤色和面部细节、真实的光影效果,以及精细的衣物纹理。与 SDXL 相比,它用更少的提示词就能生成更逼真的人物。
但同时也有一些局限性需要考虑:不适合奇幻或风格化艺术创作,且在不同风格的灵活性上较弱。
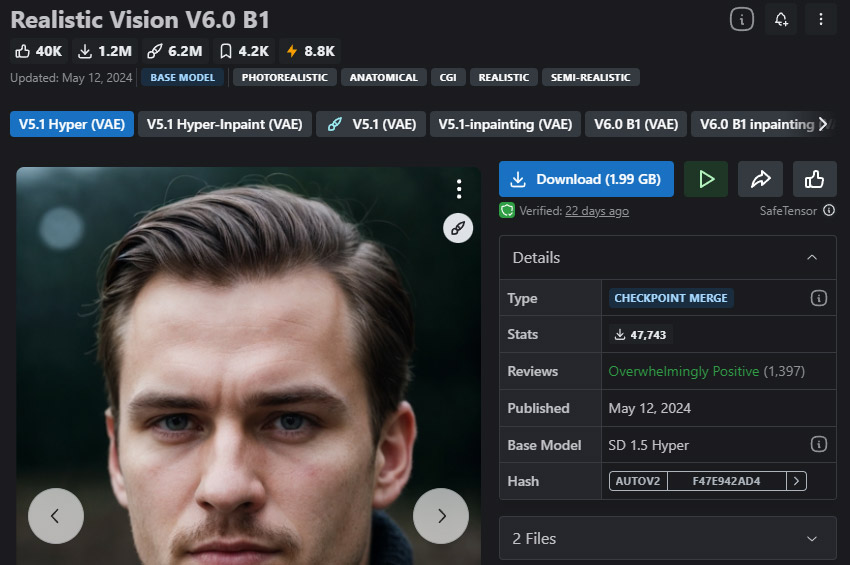
- 极其适合生成逼真的人物。
- 生成的图像细节丰富、真实感极强。
- 支持 NSFW。
- 提供 Inpainting 版本。
- 无法生成奇幻类场景或图像。
DreamShaper — 奇幻与插画风格的首选
最适合奇幻、插画和科幻场景的 Stable Diffusion 模型。
DreamShaper 是追求超凡世界视觉风格(如科幻和赛博朋克)的首选。凭借其独特的设计,它擅长呈现神秘的场景、奇幻的生物和充满想象力的风景。DreamShaper 精心设计,旨在创作具有艺术感的视觉作品,灵感来源于写实画风下的动漫风格。其出色的能力在于,能够以惊人的背景衬托出栩栩如生的角色。
这款 Stable Diffusion 模型非常适合生成跨越多种主题的图像,从写实描绘到创意梦幻构图,涵盖独特的生物、动物、物体、风景等。
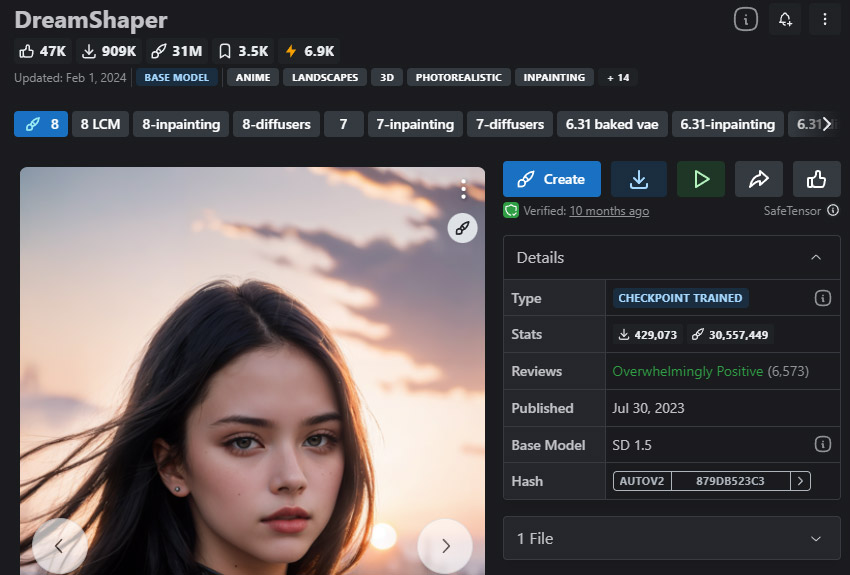
- 在科幻和赛博朋克主题创作上表现出色。
- 兼顾写实与动漫风格,适用性强。
- 提供 Inpainting 版本。
- 支持 NSFW。
- 不适合用于生成写实图像。
Anything v5 — 动漫风格的最佳选择
最适合动漫风格和卡通外观的 Stable Diffusion 模型。
Anything v5 是一款定制化的 Stable Diffusion 模型,旨在创作引人入胜的视觉作品,唤起你最喜爱的动漫和漫画的精髓。你可以期待鲜艳的色彩、富有表现力的角色以及充满活力的构图,为动漫世界注入生机。该模型尤其擅长构建日式动漫中常见的场景。
Anything v5 能够以动漫或插画风格塑造角色与风景。在生成人像时,它尤其擅长创作带有丰富精致设计元素的年轻主角。尽管外观偏向动漫风格,Anything v5 同样能够以柔和的色调打造出美丽的场景。
- 涵盖多种动漫艺术风格。
- 生成带有真实感的动漫角色和背景。
- 能够创作色彩鲜艳、活力十足的画面。
- 能够生成复杂的形状和元素。
- 支持 NSFW。
- 偏向于生成女性角色。
- 倾向于构建日式风格的典型场景。
- 使用 VAE 时可能需要一定尝试。
Juggernaut XL
最适合摄影风格图像 / 真实照片的 Stable Diffusion 模型。
对于希望突破 SDXL 模型极限的用户来说,Juggernaut XL 是一个出色的继承者。其精炼版本提供了增强的细节和保真度,非常适合生成超写实图像,将数字艺术与摄影无缝融合。它捕捉精细细节的卓越能力,使其成为创作各种主题(从全身人物、物体、标志到风景)的宝贵工具。这对于制作需要独特且无与伦比效果的写实人像或时尚插画尤其有利。
Juggernaut XL 通过针对电影级图像的专门训练进行了升级,提升了生成图像的自然感和电影质感。对于那些希望创作出捕捉真实照片精髓图像的人来说,Juggernaut XL 提供了沉浸式的体验。
- 非常适合生成逼真的静态照片和具有电影感的画面。
- 轻松处理不同尺寸的图像。
- 兼容 SDXL LoRA 模型。
- 支持 NSFW。
- 资源消耗较大。
- 输出并非总是完全写实。
- 学习曲线较陡。
2026 年依然领先的 Stable Diffusion 模型
Stable Diffusion 生态持续演进,2026 年已经涌现出令人兴奋的进展。从针对硬件优化的发布到新一代编辑能力,以下是你需要了解的重大更新。
LoRA 模型(低秩自适应)
LoRA 模型已成为 Stable Diffusion 生态的核心组成部分。LoRA 并非取代基础模型,而是作为轻量级插件,将特定的风格、角色或概念注入到 SD 3.5 Large 等模型中。这使得 LoRA 非常适合希望保持灵活性,又无需管理多个大型模型的创作者。
LoRA 模型的主要特点:
- 轻量级模型扩展,通常只有几百 MB,而基础模型通常为多个 GB。
- 设计用于添加或修改特定元素,如艺术风格、角色、服装或光照。
- 可堆叠且可调节,允许多个 LoRA 以不同强度值组合使用。
- 与 SD 3.5 Large、SDXL 及微调变体等现代基础模型完全兼容。
SD 3.5 Large
SD 3.5 Large 代表了从 3.0 系列的重大飞跃,强调跨多种风格的质量和多样性。与此同时,SD 3.5 Medium 为日常创作者提供了一个均衡的选择,而 SD 3.5 Large Turbo 则专注于速度,在细节略有精简的情况下实现更快的迭代。这些变体共同使 SD 3.5 系列适用于从爱好者到行业专业人士等不同层次的用户。
SD 3.5 Large 的主要特点:
- Stability AI 2025 年产品线中的旗舰发布,基于更广泛的数据集训练,并针对更高保真度进行了优化。
- 相比早期版本,能生成更精确、更细腻、风格范围更广的图像。
- 专为专业用途设计,对创意和商业项目都有强大的支持。
Flux 系列(Flux 1.1 → Flux 2)
Flux 系列代表了现代扩散模型中最重要的一次演进之一,从广受欢迎的 Flux 1.1 系列发展到更先进、更稳定的 Flux 2。每一代都专注于创意表现力、电影级风格和提示词灵活性——而 Flux 2 在连贯性、细节质量和速度方面引入了重大改进。Flux 系列共同为艺术家、设计师和创作者提供了广泛的选择,使他们能够在不同风格和分辨率下获得一致的控制。
Flux 1.1 系列:
- Flux 1.1 Pro: 一款均衡的专业模型,设计用于广泛的提示词覆盖和电影级渲染。
- Flux Ultra: 针对高分辨率输出优化,支持高达 4MP 的清晰生成。
- Flux Raw: 专注于写实风格,提供逼真的皮肤纹理、光照和摄影级细节。
- Flux Kontext(2025): 引入了上下文感知编辑和更智能的场景理解,适用于高级工作流。
Flux 2 的改进:
- 更强的连贯性: 更准确地处理多主体场景、手部和复杂构图。
- 更锐利的输出质量: 相比 Flux 1.1,纹理、光照过渡和整体保真度得到增强。
- 更快的推理速度: 效率优化,可在创意和商业项目中实现更快的迭代。
- 更好的提示词对齐: 减少结果偏差,对描述性提示词的响应更可预测。
- 保留 Flux 标志性美学: 延续了使 Flux 1.1 广受欢迎的电影级、富有表现力的视觉风格。

更多备受青睐的 Stable Diffusion 模型
即便新模型不断涌现,2024 和 2025 年那些久经考验的经典模型依然保持着高度的相关性。RealVisXL 和 AAM XL AnimeMix 在其细分领域中占据主导地位,而 Playground v2.5 和 ThinkDiffusion XL 则提供了艺术多样性和技术上的卓越表现。它们稳定、可靠,在 2026 年依然值得你投入时间。
- RealVisXL V4.0: 在写实人物与物体渲染方面,依然是顶级的 XL 模型之一。
- AAM XL AnimeMix: 持续领跑,成为动漫风格的必备模型。
- Playground v2.5: 因其高度艺术性和创意输出而备受赞誉。
- ThinkDiffusion XL: 生成清晰 4K 分辨率图像的强力选择。
进一步提升你的 Stable Diffusion 生成效果
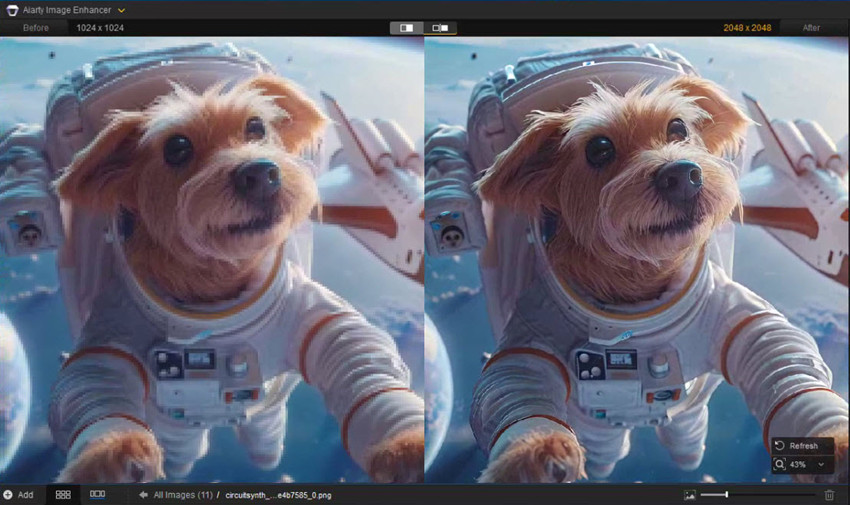
即使是最好的模型,生成的图像也可能带有噪点、模糊或压缩伪影。如果你希望将输出结果用于专业用途(例如打印、产品图或作品集),可以对图像进行放大处理至 4K 或更高分辨率、去除噪点和模糊、恢复精细细节。这时,Aiarty Image Enhancer 就能显著改善你的最终成图质量。
40+ 款 Stable Diffusion 模型清单
如果你想在头部推荐之外进行更多探索,以下按风格分类列出了更全面的 Stable Diffusion 模型清单。
小提示: 与其尝试所有模型,不如从 2-3 个核心模型(例如 SDXL 加上一个专项模型)开始,再结合 LoRA 进行扩展。
| 图像风格 | 模型名称 | 模型类型 | 基础模型 |
|---|---|---|---|
| 写实:产品 | SDXL Product Shot | LoRA | SDXL 1.0 |
| 写实:人物 | ChilloutMix | LoRA | SD 1.5 |
| 写实:风景/动物 | NextPhoto | Checkpoint | SD 1.5 |
| 写实:游戏/建筑 | RealVisXL | Checkpoint | SDXL 1.0 |
| 写实:夜景 | NightVisionXL | Checkpoint | SDXL 1.0 |
| 写实:美食 | Food Photography | LoRA | SD 1.5 |
| 写实:时尚 | Modern Vision | Checkpoint | SD 1.5 |
| 人像 | Modelshoot | Checkpoint | SD 1.5 |
| 漫画 | MANGA (General) | LoRA | SD 1.5 |
| 动漫艺术 | VaporWaveV1 | LoRA | SD 1.5 |
| 卡通 | ToonYou | Checkpoint | SD 1.5 |
| 漫画书 | Comic Diffusion | Checkpoint | SD 1.5 |
| 像素艺术 | Pixel Art XL | LoRA | SDXL 1.0 |
| 插画 | Vector Art | Checkpoint | SD 2.1 |
| 未来主义 | Futuristic XL | LoRA | SDXL 1.0 |
| 赛博朋克 | CyberpunkAI | LoRA | SD 1.5 |
| 科幻 | Sci-fi XL Style | LoRA | SD 1.5 |
| 超现实主义 | ColorfulSurrealismAI | Checkpoint | SD 1.5 |
| 复古 | RetroMix | Checkpoint | SD 1.5 |
| 怀旧 | PhotoVintageV1.5 | Checkpoint | SD 1.5 |
| 油画 | Oil Painting | LoRA | SD 1.5 |
| 水彩 | Watercolor | LoRA | SD 1.5 |
| 铅笔画 | Pencil Drawing | LoRA | SDXL 1.0 |
| 涂鸦 | Flonix’s Vector Style | Checkpoint | SDXL 1.5 |
| 漫画夸张画 | Krueger Caricature Style XL | LoRA | SDXL 1.0 |
| 电影感 | Juggernaut Cinematic XL | LoRA | SDXL 1.0 |
| 散景 | Copax Bokeh | LoRA | SD 1.5 |
| 3D 风格 | 3D Rendering Style | LoRA | SD 1.5 |
| 室内设计 | InteriorDesignSuperMix | Checkpoint | SD 1.5 |
| 装饰艺术 | Art Deco Fusion | LoRA | SD 1.5 |
| 扁平设计 | Lineart Flat Colors | LoRA | SD 1.5 |
| 低多边形 | Low Poly | LoRA | SDXL 1.0 |
| 线条艺术 | Niji Lineart | LoRA | SD 1.5 |
| 矢量艺术 | vector-art | Checkpoint | SD 2.1 |
| 哥特 | GothicpunkAI | LoRA | SD 1.5 |
| 建筑 | ArchitectureRealMix | Checkpoint | SD 1.5 |
| 野兽派 | Paragon | Checkpoint | SD 1.5 |
| 文艺复兴 | Renaissance XL | LoRA | SDXL 1.0 |
| 剪纸 | Papercut SDXL | LoRA | SDXL 1.0 |
| 剪影 | Silhouette | LoRA | SD 1.5 |
| 荧光 | Fluorescent Green | LoRA | SD 1.5 |
| 彩虹色 | Made Of Iridescent Foil | LoRA | SD 2.1 |
在哪里寻找最适合的 Stable Diffusion 模型?
在探索 Stable Diffusion 时,了解在哪里能找到高质量的模型可以节省时间并提升创作效果。以下是几个主要的来源:
- Civitai: Stable Diffusion 模型最大的社区中心。你可以在这里找到模型、LoRA、文本反演模型等。直接访问 civitai.com,进入“模型”版块,然后按模型名称、类型、基础模型或状态进行筛选。小提示:建议专注于 3-5 个核心模型,以免选择困难,并通过 LoRA 进行精细化调整。
- Hugging Face: 提供官方模型和实验性版本,是探索前沿新模型的好选择。
- Stability AI: 提供官方 SDXL 和 SD 3.0/3.5 版本,确保可靠性能与兼容性。
- Ikomia / AI 博客: 适合查看模型横向对比、基准测试以及了解不同模型在实际应用中的表现。
 Stable Diffusion 模型常见问题解答
Stable Diffusion 模型常见问题解答
目前最强大的 Stable Diffusion 模型是 SD 3.5 Large、Flux 2 和 Z-image。SD 3.5 Large 整体保真度最高,Flux 2 在电影级画质和画面连贯性上表现最佳,而 Z-image 则以快速生成和高写实度见长。具体选择哪一款,取决于你对画质精度、风格控制还是生成速度的优先级考量。
Realistic Vision 是 Stable Diffusion 中最优秀的写实模型。它尤其擅长生成具有真实面部和眼神的逼真人物。
Anything V5 是最佳的 Stable Diffusion 动漫模型,适合创建动漫风格或卡通外观的角色和场景。不过,它更侧重于构建日式风格的典型画面。查看更多 Stable Diffusion 动漫模型 >>
Stable Diffusion 使用一种称为“扩散模型”的 AI 模型,具体是由慕尼黑大学 CompVis 研究组开发的潜在扩散模型(LDM)。该模型专为高质量图像合成而设计,属于生成式模型的一种。
获取 Stable Diffusion 模型主要有两个渠道:Civitai 和 Hugging Face。